Лекция 4. Репликация в многопользовательских БД
**1.1. Определение репликации базы данных.**
Понятие репликация, в вычислительной технике неразрывно связано с процедурой копирования. По своей сути ***репликация*** – это механизм синхронизации содержимого нескольких копий одного объекта. В разговоре про многопользовательские базы данных под этим объектом понимается база данных. Суть репликации данных – тиражирование изменений данных, произошедших на одном сервере, на все связанные репликацией сервера.
Исторически, репликация связана с определением распределенной базы данных. Распределённая база данных (DDB) - база данных, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Данные представляют собой DDB, только если они связаны в соответствии с некоторым структурным формализмом (правилами проектирования), реляционной моделью, а доступ к ним обеспечивается единым высокоуровневым интерфейсом.
Центральная идея ***распределенной базы данных*** – доступность данных в любое время, в любом месте.
Очевидно, что возникновению феномена распределенных баз данных способствовал рост крупных компаний. Они открывали филиалы в новых городах, странах и даже на новых для себя континентах. IT-инфраструктура этих компаний усложнялась, доступ к данным, обращающимся внутри системы существенно замедлялся и усложнялся. В этих обстоятельствах и зародилась идея создания распределенных баз данных, которые создавали существенные преимущества для крупных и разросшихся до невероятных размеров компаний. Перечислим ключевые из них:
• Данные доступны людям, которым они нужны, и когда они нужны.
• Система позволяет локальному пользователю автономно оперировать данными (нет лишних проблем с параллельной обработкой данных, см. лекция 2).
• Система, с точки зрения общей IT-архитектуры организации, сокращает сетевой трафик.
• Процесс обеспечения непрерывности бизнеса с точки зрения БД дешевле (значительно большее количество точек хранения данных ускоряет процесс восстановления после критических сбоев).
Далее будут рассмотрены три основных инструмента обеспечения функционирования распределенных баз данных – распределенная транзакция, репликация и шардинг. Особо внимание, ввиду наибольшей актуальности будет уделено репликации.
**1.2. Распределенная транзакция и репликация.**
Самой первой технологией управления распределенными базами данных стали так называемые распределенные транзакции. Распределенная транзакция – транзакция, по определенным правилам собирающая в себе все актуальные изменения, которые происходят в распределенных базах данных, а затем управляющая процессом синхронизации массивов данных на всех узлах распределенных баз данных.
Ключевым инструментом при осуществлении распределенных транзакций является Менеджер глобального восстановления (или проще - координатор). В ходе двухфазового подтверждения (все ли узлы готовы принять новые данные; везде ли распределенная транзакция завершилась успешно), этим менеджером осуществляется реализация актуальной распределенной транзакции на всех узлах распределенной сети. Схематично, распределенная транзакция показана на рис. 1.

Обратите внимание на то, что процедура распределенной транзакции не закончится, пока координатор-менеджер не убедится в том, что транзакция была успешно выполнена на всех узлах распределенной базы данных. А представим, что этих узлов не 4-5, а 50-60. Какова вероятность быстро и успешно закончить распределенную транзакцию? Именно по причине наличия такого ограничения, в случае необходимости работы с распределенными базами данных администраторы предпочитают настраивать один из вариантов репликации.
В настоящее время, помимо указанного выше требования «данные должны обрабатываться там, где они находятся», выделяют 4 основных причины применения инструмента репликации при обеспечении работы базы данных организации.
1. Производительность и масштабируемость. Снятие с основного сервера базы данных части нагрузки по обработке данных. В основном это касается делегирования вспомогательным серверам инструкций по чтению и обработке данных. Чем больше операций чтения приходится на одну операцию записи, тем больше выгоды от репликации.
2. Отказоустойчивость. Если вдруг по какой-то причине, один или несколько вспомогательных серверов баз данных в репликации перестанут функционировать, главный сервер тут же может «перехватить» на себя операции, которые ранее выполняли вспомогательные серверы. Такие действия возможны и в обратном направлении, когда вспомогательный сервер на время выполняет функции записи и хранения данных, характерные для основного сервера.
3. Резервное копирование данных. Существенно упрощается работа администратора, связанная с необходимостью создания резервных копий (Лекция 3). Зачастую можно даже не руководствоваться бизнес-требованиями и планами резервного копирования. Дело в том, что вспомогательный сервер в репликации можно остановить и снять резервную копию в любое время.
4. Отложенные вычисления. Огромные по объему SQL запросы, которые регулярно и очень сильно нагружают вычислительные мощности основного сервера выгодно выполнять на отдельном вспомогательном сервере.
Приведем основную терминологию, применяемую в репликации.
***Издатель*** - основной сервер баз данных в репликации. В большинстве случаев ориентирован на процедуры, связанные с записью и хранением данных.
***Подписчик*** – вспомогательные серверы баз данных в репликации. В большинстве случаев ориентированы на процедуры, связанные с чтением и обработкой данных.
***Распространитель*** – скрипты, осуществляющие репликацию данных между издателем и подписчиками.
***Публикация*** - информация, которая подвергается репликации. Одна публикация – это один согласованный набор данных.
В состав публикации входят статьи, которые могут быть:
- целой таблицей или ее частью;
- хранимой процедурой или представлением;
- пользовательской функцией.
Отметим, что для публикаций и статей (как для единиц данных для репликации) существует ряд важных ограничений.
• Статья содержит данные из таблицы и одной или нескольких хранимых процедур.
• Таблица может быть как целой, так и подмножеством.
• В публикации можно собрать несколько статей.
• Каждая публикация должна содержать данные только из одной базы данных.
• Подписаться на статью нельзя.
На рис. 2 показаны фильтры, которые можно применить при формировании массива данных для статьи.
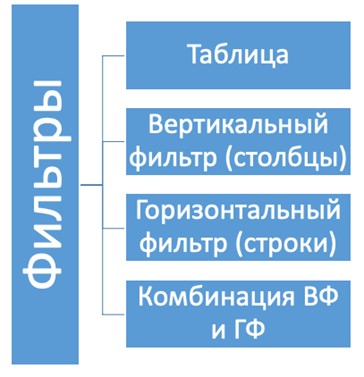
Так, в состав статьи может входить таблица данных целиком, выборка из таблицы с условием по столбцам, выборка из таблицы с условием по строкам, выборка из таблицы с комбинацией условий по столбцам и строкам.
Инициализация подписки происходит push (принудительная) или pull (запрос) методом. Описание типов подписок показано на рис. 3.
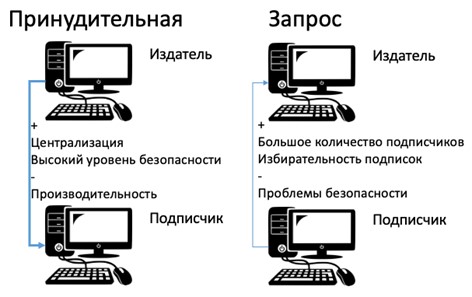
Ключевым различием в типах подписок является направление подписки. В случае ***push (принудительной) подписки***, издатель обязует подписчика принять направленные ему публикации. Ключевой проблемой при этом является производительность распределенной базы данных, поскольку управление всеми подписками происходит централизованно, на стороне издателя.
В случае ***pull (запроса) подписки***, подписчик запрашивает необходимые ему публикации, и издатель в ответ их предоставляет. Ключевой проблемой является проблема безопасности, поскольку у большого количества подписчиков появится возможность формировать запросы к издателю.
**1.3. Типы репликации MS SQL Server 2018.**
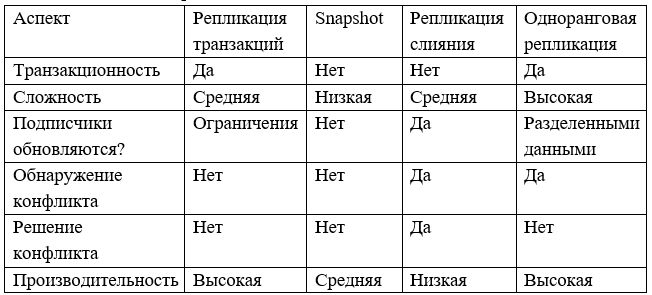
1. ***Репликация транзакций.*** Все транзакции, которые отмечены для репликации «вылавливаются» из журналов транзакций агентом чтения журналов (Log reader agent), после чего копируются в специальную системную базу данных distribution. Далее, с помощью распространителя (Distribution agent), транзакции распределяются по подписчикам, где и исполняются. Существует два ограничения, которые должны быть соблюдены при реализации такого варианта репликации:
• перед настройкой репликации транзакций каждый Подписчик должен получить и развернуть полную резервную копию Издателя у себя;
• у каждой реплицируемой таблицы должен быть первичный ключ.
Схематично репликация транзакций показана на рис. 4.

2. ***Репликация мгновенного снимка (snapshot).*** Репликация осуществляется не по необходимости, а периодически, в рамках заранее настроенного интервала времени. Компонент СУБД Snapshot Agent генерирует схему и пакет данных для таблиц входящих в Публикацию, и агрегирует их в один файл, после чего, этот файл передается Подписчикам. Ряд условий, сопровождающих данный вид репликации:
• база данных Distribution, в отличие от случая репликации транзакций, напрямую не используется;
• при репликации мгновенного снимка возможен только один тип подписки - от Издателя к Подписчику;
• наличие первичного ключа в реплицируемых таблицах не обязательно. Схематично репликация мгновенного снимка показана на рис. 5.

3. ***Репликация слияния (merge).*** Данный вид репликации во многом дублирует репликацию мгновенного снимка, за исключением этапа, когда специальный Merge Agent изменяет файлы, содержащие схему и пакет данных для Публикации перед тем, как передать их Подписчикам. К файлу Публикации добавляются системные таблицы, первичные ключи (где это необходимо) и системные триггеры. Происходит этого для того, чтобы обеспечить оба типа подписки – как push, так и pull. Из-за существенных изменений в файле Публикации, при обновлении серверов могу возникать конфликты, которые будут решаться проверкой приоритетов (по умолчанию – «первый побеждает») или действиями пользователя.
Схематично репликация слияния показана на рис. 6.

4. ***Одноранговая репликация (peer-to-peer).*** Вид репликации, при котором все серверы баз данных, участвующие в репликации не имеют четкого иерархического разделения. Перечислим особенности данного типа репликации:
• все серверы баз данных, участвующие в репликации настроены с возможностью функционирования как издатель-распространитель-подписчик и по необходимости могут переключаться в любой режим работы;
• все серверы обладают одним и тем же набором и схемами данных, постоянно синхронизируя их друг с другом;
• каждый сервер манипулирует своим подмножеством данных, передавая его в режиме издателя остальным подписчикам;
• любой конфликт обновления при передаче Публикации будет считаться ошибкой, требующей исправления.
Схематично репликация слияния показана на рис. 7.

Сравнительное описание типов репликации показано в табл. 1.
Практическая реализация механизма репликации сервера баз данных MS SQL Server 2018, в соответствии с технической документацией, рекомендуется с использованием Management Studio и встроенного мастера настройки агентов репликации. Практическая работа с мастером будет разобрана в ходе лабораторных работ курса. Более подробно про объекты автоматизации будет рассказано в материале Лекции 5.
1.4. **Настройка репликации и шардинга в MongoDB.**
Отдельно следует рассмотреть базовые принципы репликации для noSQL структуры хранения данных. Как правило, noSQL модель используется в случае обработки параллельных массивов больших данных, что, в большинстве случаев создает предпосылки к репликации хранимых данных. В документной СУБД MongoDB выделяют два способа управления распределёнными данными – репликация и шардирование (шардинг).
Оптимальный подход к репликации в MongoDB – асинхронная репликация с тремя узлами. Свойство асинхронности говорит о том, что синхронизация данных Издателя с Подписчиками происходит не в режиме реального времени, а с задержкой. Очевидно, что это позволит не увеличивать и без того огромную нагрузку на сервер данных и на сетевое оборудование. Три узла репликации – это соответственно Издатель, Подписчик и Арбитр.
Издатель – первичный узел хранения данных.
Подписчик – вторичный узел хранения данных.
Арбитр – узел, не содержащий массива данных, но обеспечивающий принятие решения об изменении свойств первичного и вторичного узла (например, в случае временной недоступности первичного узла хранения).
У данной структуры есть одна важная особенность – очень нежелательно узел Арбитр размещать на одном из узлов хранения. Это связано с автоматической системой опроса Арбитром узлов хранения, которая называется Сердцебиение (heartbeats), которая, в случае отсутствия отклика со стороны узла хранения позволяет Арбитру считать его вышедшим из строя и включает функцию изменения статуса других узлов хранения, находящихся в строю. Соответственно, если Арбитр будет находиться на одной машине с вышедшим из строя узлом хранения, он свои автоматизированные функции выполнять не сможет.
Рассмотрим процедуры MongoDB, использующиеся при создании и обеспечении функционирования репликации. Для создания схемы репликации, описанной выше, необходимо выполнить следующие шаги.
1. Создание узлов, участвующих в репликации. Как минимум необходимо создать три узла командой:
mongod --replSet /название репликации, одно для всех узлов/ --host /адрес сервера базы данных/ --port /номер порта базы данных/ --dbpath /путь к категории базы данных, созданной заранее/.
2. Инициация первичного узла хранения. Запустив терминал MongoDB на узле-сервере, который будет служить как первичный, необходимо выполнить команду rs.initiate(), которая устанавливает выбранный узел в режим Primary (первичный).
3. Добавление вторичного узла хранения. Происходит также в терминале первичного узла-сервера выполнением команды rs.add(«адрес вторичного сервера:порт вторичного сервера»).
4. Добавление узла Арбитр. Происходит также в терминале первичного узла-сервера выполнением команды rs.add(«адрес сервера арбитра:порт сервера арбитра», {arbiterOnly: true}).
В отличие от репликации, шардирование MongoDB – это разделение большого массива данных между несколькими узлами. Эта функция будет полезна при обработке и хранении действительно больших объемов данных (например петабайт), с чем вряд ли справится один отдельно взятый сервер. При этом, интерфейс MongoDB позволяет работать со всей совокупностью шардов (кусочков данных, разнесенных по нескольким серверам), как с базой данных, расположенной на одном сервере.
Для настройки шардинга проделывают следующие процедуры.
1. Запуск конфигурационного сервера, маршрутизирующего потоки данных между шардами командой mongod --configsvr --dbpath /путь к категории базы данных, созданной заранее/ --port /номер порта базы данных/
2. Настройка маршрутизации с конфигурационным сервером командой mongos --configdb --host /адрес сервера базы данных/ --port /номер порта базы данных/
3. Создание шардов командой mongos> sh.addShard(«адрес сервера базы данных:номер порта базы данных»), повторяем выполнение команд столько раз, сколько необходимо шардов.
4. Запуск шардинга командой mongos> sh.enableSharding(«название коллекции подлежащей шардингу»).
Попробовать создать структуру репликации и шардинга mongoDB студенты смогут, выполнив самостоятельную домашнюю работу по материалам данной лекции.
1.5. **Вопросы для самостоятельного изучения по итогам лекции.**
1. Как называется сервер, который содержит полную актуальную копию мастер-сервера БД? В каких случаях используется?
2. Компания имеет филиалы в разных городах. В каждом филиале есть свой сервер БД, который имеет такой же набор данных, что и остальные. Какую репликацию данных стоит реализовать в данном случае. Почему?
3. В чем отличие репликации от шардинга в MongoDB?
4.6. Тестовые задания для самопроверки.
1. Какой из приведенных терминов не относится к технологии репликации данных?
А) тираж
Б) издатель
В) статья
Г) подписчик
2. Какой из перечисленных фильтров не может быть применен для формирования статей при репликации?
А) горизонтальный
Б) вертикальный
В) таблица
Г) все перечисленные могут быть использованы
3. В каком из перечисленных типов репликации допустимо формирование публикаций на стороне подписчика?
А) репликация слияния
Б) репликация мгновенного снимка
В) репликация транзакций
4. В каком из перечисленных типов репликации издатель является одновременно и подписчиком?
А) одноранговая репликация
Б) репликация слияния
В) репликация мгновенного снимка
Г) репликация транзакций
5. При какой репликации необходима передача полной резервной копии издателя подписчику?
А) одноранговая репликация
Б) репликация слияния
В) репликация мгновенного снимка
Г) репликация транзакций
6 Какой из перечисленных критериев не характерен для термина распределенные данные?
А) есть возможность автономного оперирования данными
Б) доступ к данным в точке их получения-хранения
В) система увеличивает сетевой трафик
Г) все критерии характерны
7 Распределенной транзакцией управляет…
А) координатор
Б) мастер
В) репликатор
Г) распространитель
8 Какое из перечисленных ограничений статей неверное?
А) статья содержит данные из таблицы
Б) несколько статей, это публикация
В) подписаться на статью нельзя
Г) все ограничения верны