Лекция 1. Введение в администрирование. Перепроектирование баз данных
***1.1. Причины перепроектирования многопользовательских баз данных***
Специалисты выделяют две основные причины перепроектирования
многопользовательских баз данных.
***Первая причина*** – это проблема комплексности (сложности) проекта
многопользовательской базы данных. Весьма непросто выполнить
проектирование базы данных без ошибок с первого раза. Это касается даже
компактных моделей баз данных для небольших приложений. Что уж говорить
о сложных моделях для интернет-бизнеса или для принципиально новых
информационных систем. Даже при наличии подробного технического задания,
правильной и понятной логической модели, при реализации физической модели
в выбранной СУБД с большой вероятностью могут возникнуть разного рода
проблемы. Если проект базы данных очень большой, то такой проект может
потребовать даже несколько стадий (слоев) проектирования и
перепроектирование уже готовых элементов физической модели, в ходе
реализации последующих этапов проекта – это стандартная практика.
Аналогично проектированию, процесс исправления ошибок, допущенных при
моделировании баз данных – это обычная и правильная практика
проектирования и эксплуатации многопользовательских баз данных.
***Вторая причина*** – это взаимное влияние информационных систем и
организаций друг на друга. Манифесты DevOps, ITIL, CobIT уже давно
декларируют взаимное эволюционное изменение IT-инфраструктуры
организаций и их организационной архитектуры. Когда внедряется новая
информационная система – пользователи подстраиваются под нее. Со временем,
сами пользователи (организация) начинают подстраивать информационную
систему под свои нужды. Этот процесс эволюционных взаимных изменений
становится перманентным. И такими же перманентными становятся изменения
в структуре физической модели многопользовательской базы данных.
Приведем стандартные причины перепроектирования
многопользовательских баз данных:
1. Увеличение компании за счет новых дивизионов.
2. Выход компании на новые рынки.
3. Добавление новых продуктов или услуг.
4. Переход компании на новую форму функционирования.
7
5. Внедрение новых политик безопасности информации.
6. Внедрение новых политик по принципам хранения информации
7. etc.
Развитие, расширение сферы деятельности компании всегда ведет за собой
существенные изменения в ее IT-инфраструктуре и информационных системах.
На рис. 1 показаны изменения, произошедшие в последние несколько лет в
компании Amazon.
Начав свою операционную деятельность, как компания, предоставляющая
услуги при продаже книг (посредник для вендоров, печатающих и продающих
книжную продукцию), компания в сравнительно короткий срок
диверсифицировала свою деятельность и в настоящий момент времени не только
продает и отправляет всевозможную продукцию от тех же книг до автомобилей
Феррари, но и предоставляет огромное количество сервисов и услуг, связанных
с распространением и продажами медиаконтента.
Сервис AWS (Amazon Web Services) в настоящее время – одна из самых
популярных платформ облачных вычислений для коммерческих и
государственных сервисов.
Продавая только книги, компании Amazon, в рамках структуры их базы
данных достаточно было в качестве первичных ключей использовать названия
компаний-вендоров. Очевидно, что после диверсификации продаж,
использовать названия компаний стало проблематичным, из-за появления
названий-дубликатов. В сложившейся ситуации, чтобы не допустить конфликта
экземпляров сущностей в базе данных, возникает необходимость
перепроектирования баз данных в сторону изменения первичных ключей
сущностей (вероятно, переход на собственные кодированные идентификаторы
вендоров Amazon).
Так что же произойдет, если нам необходимо поменять существующий
набор ключей в таблице? Во-первых, добавится список новых ключевых
значений, запланированных при перепроектировании. Но это далеко не все.
Помимо измененных первичных ключей, должны быть изменены и все внешние
ключи, связанные с первичными. Для этого необходимо знать, в каких связях
участвовал старый первичный ключ. Тоже самое касается и созданных в базе
данных представлений. Не забываем и про триггеры и хранимые процедуры,
которые также могли быть «завязаны» на старом первичным ключе. Все
приложения баз данных, которые использовались компанией, тоже могут быть
чувствительны к старым значениям первичного ключа и также должны быть
пересмотрены при перепроектировании.
И при всем вышеперечисленном, все действия, описанные выше должны
быть произведены без ошибок с обеспечением непрерывности бизнеса компании.
Можете вы представить на странице веб-приложения Amazon сообщение
«Простите, у нас сломалась база данных, - заходите завтра (но это неточно)»?
Это все накладывает серьезные требования и ограничения на каждую
процедуру перепроектирования баз данных. Квалификация администратора
должна позволять безошибочно и в срок выполнять эту функцию.
С точки зрения администрирования баз данных, процедура
перепроектирования относится к ***SDLC (systems development life cycle)*** и
регламентируется тремя основными принципами:
- «семь раз отмерь, один раз отрежь». Тщательная неоднократная
проверка решений по перепроектированию, перед их имплементацией;
- предварительное тестирование всех изменений на тестовой базе
данных с проходкой основных тестовых дата-кейсов;
- полное резервное копирование изменяемой базы данных (об этом будет
подробнее рассказано в материале лекции 3 этого пособия).
***1.2. Инструментарий исследования физической модели данных***
Подготовка к процедуре перепроектирования базы данных начинается с
изучения физической модели базы данных. Для получения компактной и
информативной модели используются ***практики обратного инжиниринга***
(reverse engineered, RE) и составления ***графов зависимостей*** (dependency graph).
Обратный инжиниринг – это процесс чтения схемы физической модели
базы данных и формирование модели данных в качестве результата. Полученная
модель не является логической, поскольку может содержать элементы, для этой
модели неприсущие (физические типы данных с пользовательскими
ограничениями; пересечения таблиц, не имеющие ключевых значений и т.д.).
Данные модели формируются в специализированном программном обеспечении
в автоматическом режиме, после процедуры настройки мастера (ErWin Data
Modeler, MySQL Workbench). Образец RE-модели, созданной в программном
средстве ErWin Data Modeler в результате чтения реляционной базы данных
приложения msuniversity.ru показан на рис. 2.
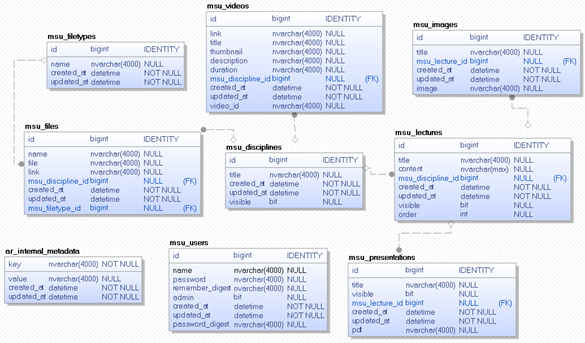
На RE-модели можно увидеть структуру таблиц (не все из которых
соединены связями), описание типов связей и подробное описание столбцов
приведенных таблиц.
Однако, стоит заметить, что у инструмента RE-моделирования есть один
существенный недостаток, не позволяющий при перепроектировании баз
данных руководствоваться только им. В модели не показываются представления,
хранимые процедуры, триггеры и приложения баз данных, на которые могут
повлиять изменения в ходе перепроектирования базы данных. С целью
избавиться от этого недостатка, для проекта перепроектирования также
создается граф зависимостей.
Граф зависимостей состоит из узлов, являющихся артефактами баз данных
(таблицы, представления, триггеры, хранимые процедуры и т.д.). Узлы связаны
друг с другом многочисленными связями. Одна сторона связи показывает ее
источник, а другая – адресат. Основной задачей графа зависимости является в
компактном виде показать все связи между многочисленными элементами базы
данных. Пример графа зависимостей для фрагмента базы данных аукциона
произведений искусства, который используется нами в ходе выполнения
практических работы, приведен на рис. 3.
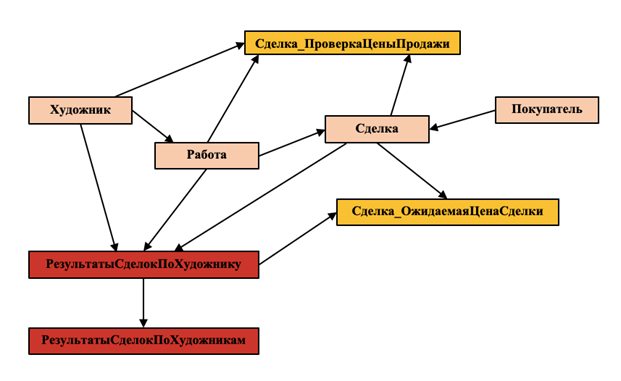
На графике «телесным» цветом показаны таблицы базы данных, оранжевым
цветом – триггеры и хранимые процедуры, а красным цветом – представления.
Очевидно, что при изменении структуры таблицы Работа (изменение свойств
первичного ключа, переименование таблицы и т. Д.), это повлияет на связь
Работа-Сделка (внешний ключ таблицы Сделка ссылается на первичный ключ
таблицы Работа), на работоспособность триггера
СделкаПроверкаЦеныПродажи и на оба представления
РезультатыСделокПоХудожнику и РезультатыСделокПоХудожникам.
Исследование графика зависимости дало нам понимание – какие элементы базы
данных будут затронуты в ходе перепроектирования, что позволит нам заранее
создать скрипт, позволяющий без рисков провести запланированное
перепроектирование.
***1.3. Инструкции перепроектирования баз данных***
Далее рассмотрим основные элементарные процедуры и инструкции языка
SQL, которые реализуются в ходе перепроектирования баз данных.
Изменение названия таблиц
Изучение БД через граф зависимостей часто показывает, что у одной
таблицы может быть несколько связанных с ней элементов. Это провоцирует
проблему переименования таблицы. Данную проблему принято решать через
создание новой таблицы, переноса всех данных старой таблицы и уничтожение
старой таблицы, потерявшей актуальность.
Пример данной процедуры, показан в описании рис. 3 выше.
Давайте предположим, что в процессе перепроектирования структуры
данных, представленной на рис. 3 таблицу Работа (Work) необходимо
переименовать в таблицу РаботаВерсия2 (Work_Version2). Это может быть
обусловлено, как было описано выше диверсификацией деятельности компании
или же изменениями в политике информационного менеджмента или
информационной безопасности компании.
Стандартный набор действий для этой процедуры, будет следующий:
1. Создаем переменные с внешними и внутренними ключами для новой
таблицы Work_Version2.
2. С помощью вложенного запроса или иным доступным способом
копируем данные из старой таблицы Work в новую Work_Version2, если
необходимо, предварительно их заменив или скорректировав.
3. Заменяем ограничения внешних ключей в других связанных таблицах (в
нашем случае, это таблица Сделка (Deal)).
4. Изменяем скрипты запросов для связанных с таблицей представлений.
5. Переписываем заново связанные с таблицей триггеры и хранимые
процедуры.
6. Если необходимо, переписываем настройки соединения приложения баз
данных и встроенный SQL-код в приложении.
Более подробно принцип изменение названия таблицы в рамках
перепроектирования баз данных будет рассмотрен в одной из практических
работ по дисциплине в текущем семестре.
Добавление и изменение столбцов существующих таблиц
Добавление новых столбцов в уже существующую таблицу сопряжено с
решением одной проблемы. Дело в том, что каждый столбец будет добавлен уже
к имеющимся экземплярам данных существующей таблицы, поэтому
проектировщик баз данных должен задать себе вопрос – каким образом (какими
данными) будет при добавлении заполняться новый столбец.
Существует два варианта решения этой проблемы.
Вариант 1. Создание столбца со свойством NULL. В этом случае, все
значения уже существующих экземпляров данных таблицы в добавляемом
столбце примут неопределенное значение NULL. Типовой скрипт этой
процедуры выглядит следующим образом:
ALTER TABLE /Название таблицы/ ADD /Название столбца/ /Тип данных столбца/ NULL;
Важно отметить, что указание типа данных при добавлении столбца
обязательно.
Вариант 2. Создание столбца со значением по умолчанию (DEFAULT). В
этом случае, все значения уже существующих экземпляров данных таблицы в
добавляемом столбце примут значение, которое будет указано проектировщиком
в скрипте. Типовой скрипт этой процедуры выглядит следующим образом:
ALTER TABLE /Название таблицы/ ADD /Название столбца/ /Тип данных столбца/ NULL DEFAULT
/значение по умолчанию/;
Значение по умолчанию должно удовлетворять требованиям указанного для
столбца типа данных и пользовательских ограничений.
Удаление столбца выполняется следующей типовой инструкцией:
ALTER TABLE /Название таблицы/ DROP COLUMN /Название столбца/;
Отдельно стоит рассмотреть случай удаления столбца первичного ключа
таблицы.
Для осуществления этого необходимо совершить следующую
последовательность действий:
1. Удалить все ограничения внешних ключей, ссылающихся на удаляемый
первичный ключ из связанных таблиц (если таковые есть).
2. Удалить ограничение первичного ключа.
3. Создать новое ограничение первичного ключа.
4. Создать новые ограничения внешних ключей, связав их с множеством
нового первичного ключа.
5. Удалить столбец, бывший первичным ключом ранее.
Изменение минимальных кардинальностей связей. Минимальные кардинальности в бинарной связи – это значения zero и one на сторонах связи между родителем и потомком. При перепроектировании
соответственно необходимо изменять zero на one или наоборот на стороне
родителя или на стороне потомка. В зависимости от стороны практикуется два
принципиально разных подхода к перепроектированию.
Изменение минимальной кардинальности на стороне родителя происходит
за счет изменения свойства NULL для внешнего ключа в выбранной связи.
Свойство внешнего ключа NULL говорит о минимальной кардинальности zero,
а свойство NOT NULL – о минимальной кардинальности one.
Для примера предположим, что имеется бинарная связь между таблицами
EMPLOYEE (сотрудники) и DEPARTMENT (подразделение). Для этой бинарной связи мы хотим изменить минимальную кардинальность с zero на one. Порядок
инструкций в скрипте, будет следующий:
ALTER TABLE EMPLOYEE DROP CONSTRAINT DepartmentFK;
ALTER TABLE EMPLOYEE ALTER COLUMN DepartmentNumber Int NOT NULL;
ALTER TABLE EMPLOYEE ADD CONSTRAINT DepartmentFK FOREIGN KEY REFERENCES
DEPARTMENT (DepartmentNumber);
Отметим, что при изменении свойства NULL внешнего ключа, как и в
случае переименования ключа, необходимо сперва удалить текущее ограничение
внешнего ключа, затем изменить свойство столбца на NOT NULL и после этого
пересоздать ограничение первичного ключа.
Изменение минимальной кардинальности на стороне потомка (речь идет
только об изменении с zero на one), необходимо написать служебные триггеры,
которые будут срабатывать на вставку (INSERT) в таблицу-родитель и на
изменения (UPDATE) и удаления (DELETE) в таблице-потомке. Обратное
изменение минимальной кардинальности потребует удаления созданных
триггеров.