Лекция 2. Управление многопользовательскими базами данных
**1.1. Определение параллельной обработки данных.**
Одной из ключевых особенностей многопользовательской базы данных является обеспечение возможности совместной работы нескольких пользователей (зачастую их количество может исчисляться тысячами или даже сотнями тысяч пользователей) с одной и той же (зачастую весьма локализованной и небольшой) совокупностью данных.
Инструментами, обеспечивающими возможности одновременной работы с данными для большого количества пользователей, обладают практически все современные реляционные СУБД, рис. 1.

В данной лекции будет рассмотрена реализация параллельной обработки данных и инструмент под названием транзакция.
***Управление параллельной обработкой данных*** – меры и мероприятия, предпринимаемые с целью ограничить влияние действий, осуществляемых пользователями во время сеанса работы с БД друг на друга. Как становится понятно из контекста – пользователи, в ходе работы с данными, если этот процесс не контролируется СУБД могут создавать друг другу существенные помехи. Первая проблема, которая может возникнуть в структуре базы данных в любой момент – это потеря ценных данных из-за возникновения в ходе обработки данных нештатной ситуации. Наглядно такого рода проблема показана на рис. 2.
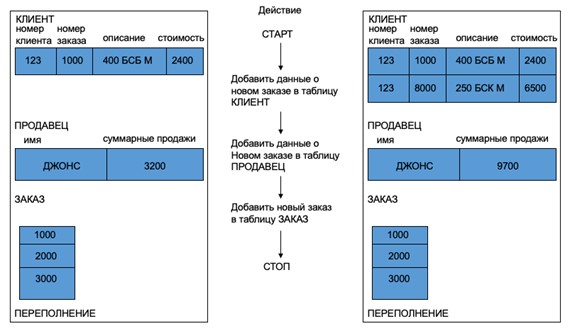
В некоторой базе данных магазина товаров для спорта есть три таблицы – КЛИЕНТ, ПРОДАВЕЦ и ЗАКАЗ. При формировании заказа, продавец через приложение последовательно вносит следующие изменения в базу данных: номер клиента, номер заказа, описание заказа и суммарная стоимость всех элементов заказа вносится в таблицу КЛИЕНТ. Стоимость последнего заказа в виде накапливаемого итога вносится в суммарные продажи в таблицу ПРОДАВЕЦ. Наконец номер заказа записывается в таблицу ЗАКАЗ и товары отправляются (передаются) клиенту. Предположим, следующую внештатную ситуацию – данные о заказе 8000 для клиента 123 были внесены в таблицы КЛИЕНТ и ПРОДАВЕЦ, а при внесении данных в таблицу ЗАКАЗ произошло переполнение физического пространства, выделенного под базу данных. Таким образом возникает ситуация, когда данные в таблицах КЛИЕНТ и ПРОДАВЕЦ останутся в измененном виде, тогда как информация для таблицы ЗАКАЗ была потеряна. Это зачастую может привести к неприятному итогу – товары со склада списаны, продавец получает премию, а заказ клиенту не отправляется.
Суть данной проблемы в том, что в приведенном примере одна функция магазина реализована последовательной вставкой нескольких экземпляров данных в разные таблицы. Очевидно, инструкции INSERT (а их будет реализовано 3) выполняются независимо друг от друга, что и провоцирует риск возникновения сложностей в процессе их обработки. Логика решения данной проблемы в следующем – если все участвующие инструкции объединить в один атомарный конструкт с правилами исполнения, то потери данных в любом случае можно избежать. Такие атомарные конструкты называются транзакции.
**1.2. Транзакции и аномалии транзакций.**
***АТ (атомарной транзакцией) или LUW (logical units of work)*** считаются серии действий, предпринимаемых с базой данных, которые выполняются успешно все целиком, или не выполняются совсем (в случае неуспеха).
В случае применения атомарной транзакции, логика реализации примера на рис. 2 будет выглядеть следующим образом (рис. 3).
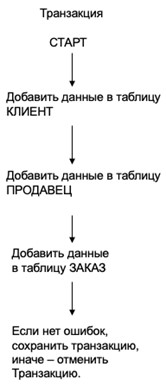
В языке SQL транзакция в базовом виде вводится следующим образом:
BEGIN /Название транзакции/
/Последовательность инструкций, входящих в транзакцию, например/
Изменить данные Клиент
Изменить данные Продавец
Вставить данные в Заказ
IF /Все и успешно/ THEN
COMMIT /Название транзакции/
ELSE
ROLLBACK /Название транзакции/
END IF
Инструкция COMMIT сохраняет все изменения, произошедшие в базе данных в ходе реализации транзакции, инструкция ROLLBACK наоборот, отказывает базу данных в состояние “до транзакции”. Дополнительные свойства транзакций будут описаны позже.
Применение транзакций при исполнении комплексных инструкций в СУБД действительно решает базовые проблемы многопользовательских баз данных. Вместе с этим, в некоторых случаях параллельное применение транзакций может стать причиной возникновения одной из пяти аномалий.
1. ***Потерянное обновление (lost update).*** Аномалия, проявляющаяся, когда несколько разных транзакций изменяют один и тот же массив данных. При фиксировании результата получается, что одна транзакция изменила и переписала данные, внесенные другой транзакцией. Рассмотрим причину и логику появления этой аномалии более подробно.
Для начала посмотрим, как СУБД обрабатывает параллельные транзакции в обычном режиме. Предположим, что два пользователя А и Б параллельно запустили две транзакции. Цель транзакции А – изменить и записать элемент 100 (значение в одной из строк таблицы базы данных), цель транзакции Б – изменить и записать элемент 200 (значение в другой строке, отличной от элемента 100). В это случае транзакции пройдут в штатном режиме, не создавая проблем с феноменами. Последовательность обработки транзакций на стороне СУБД показана на рис. 4.
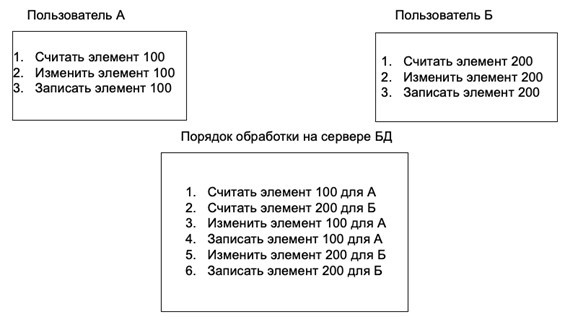
Пользователи А и Б получают в результате запроса текущее значение элемента 100 и 200 соответственно. Получивший приоритет пользователь А (например, обратился к СУБД чуть раньше) получает возможность с помощью транзакции изменить и записать изменения в элементе 100. После этого возможность изменить и записать изменения в элементе 200 получает пользователь Б. После этих инструкций БД остается в согласованном состоянии, поскольку транзакции в этом случае друг другу «не мешали».
Аномалия потерянного обновления возникнет, когда параллельные транзакции попытаются изменить и записать изменения одного и того же элемента базы данных. Пример аномалии показан на рис. 5.
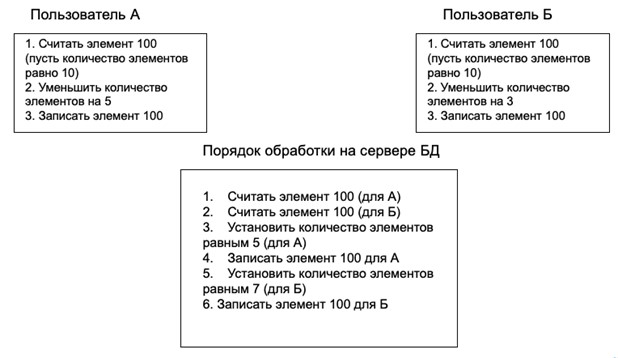
Отметим, что последовательность действий идентична тем, которые показаны на рис. 4 и для описанного случая считаются эталонными. Но, в данном случае, будет потеряна транзакция, уменьшающая количество элементов на 5 (10 – 5 = 5), поскольку сразу после нее будет выполнена транзакция, уменьшающая начальное количество элементов на 3 (10 – 3 = 7). Результат второй транзакции и станет последним записанным значением.
2. ***Грязное чтение (dirty read).*** Аномалия возникает тогда, когда одна параллельная транзакция читает данные, измененные транзакций, которая все еще обрабатывается в СУБД (этот процесс может теоретически занимать от нескольких секунд, до нескольких часов). Если транзакция, которая выполняется в СУБД сейчас будет завершения с итогом ROLLBACK (откат на стартовое состояние из-за ошибки в инструкциях), то данных, полученных параллельной транзакцией уже в системе физически не будет.
3. ***Неповторяющееся чтение (non-repeatable read).*** Аномалия проявляется тогда, когда при повторном чтении одного и того же массива данных (выполнение инструкции SELECT), транзакция получает нетождественные (разные) массивы данных. Происходит это из-за того, что в промежутке между первичным и повторным чтением данных другая транзакция уже успела их изменить. В итоге один и тот же запрос выдает различные результаты.
4. ***Фантомное чтение (phantom read).*** Похоже на случай неповторяющегося чтения, описанный выше, но между первичным и повторным чтением другая транзакция добавляет новые строки в массив данных и фиксирует изменения. В итоге, результатом выполнения запроса является другое множество строк.
5. ***Сериализация (serialization anomaly).*** Результат успешно выполненных параллельных транзакций не совпадает с результатом последовательного выполнения этих же транзакций.
1.3. Уровни изоляции транзакций и блокировки.
Решением всех перечисленных аномалий является выбор настройки параллельной транзакции (изоляции). Общий стандарт SQL подразумевает четыре возможных уровня изоляции: Read Uncommitted (незавершенное чтение), Read Committed (завершенное чтение), Repeatable Read (повторное чтение) и Serializable (сериализация). Реакция уровня изоляции на возможные аномалии показана в табл. 1.
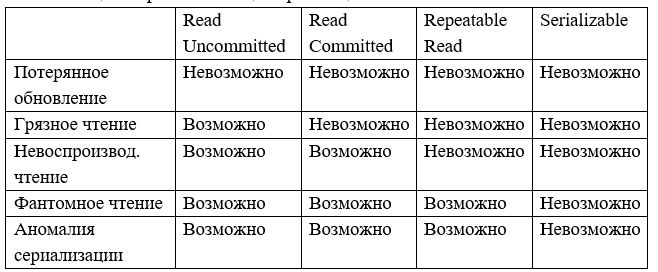
В коде инструкции SQL уровень изоляции транзакции устанавливается командой SET TRANSACTION ISOLATION LEVEL [выбор из… READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ/SERIALIZABLE]. После выбора уровня изоляции транзакции, дальнейшие действия по устранению аномалии СУБД выполнит в автоматическом режиме.
Подробнее примеры аномалий и изоляции транзакций будут разобраны на практических занятиях курса.
На уровне изоляции READ COMMITTED возможна более гибкая настройка изоляции элементов базы данных в ходе выполнения параллельных транзакции. Сделать это проектировщик запросов может с помощью инструмента Блокировка. С помощью блокировок проектировщик может заблокировать на время транзакции как таблицы базы данных, так и отдельные строки таблиц. Базовый принцип работы инструмента блокировка показан на рис. 6. Для примера выбрана ситуация, аналогичная рис. 5.
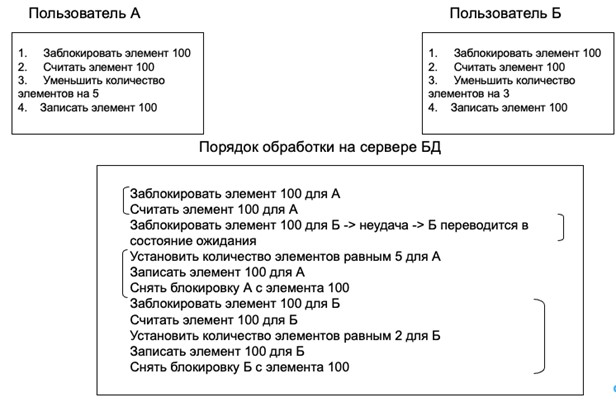
В порядке обработки на сервере «рамками» показаны изменения в последовательности действий СУБД, вызванные введенной проектировщиком блокировкой. В данном случае блокировке подлежит лишь тот элемент, что будет изменен в ходе исполнения параллельных транзакций.
В зависимости от используемой СУБД существует значительное количество разных способов наложения блокировки. Рассмотрим наиболее простой способ, с использованием инструкции LOCK. Блокировки делятся на оптимистические и пессимистические.
Принцип оптимистической блокировки: все пройдет хорошо, процесс будет успешный, конфликта транзакции не случится. Если случится конфликт – переделаем транзакцию столько раз, сколько нужно для отсутствия конфликта. Блокировка будет установлена только на время исполнения инструкций, изменяющих данные. Приведем пример скрипта, реализующего оптимистическую блокировку.
@newquantity int
SELECT product.name, product.quantity
FROM product
WHERE product.name = ‘Mountain Bike’;
SET newquantity = product.quantity – 20;
/*полагаем, что все пройдет хорошо*/
LOCK product;
UPDATE product
SET product.quantity = newquantity
WHERE product.name = ‘Mountain Bike’;
UNLOCK product;
Инструкции блокировки LOCK и UNLOCK накладываются на таблицу PRODUCT только на время выполнения инструкции UPDATE.
Принцип пессимистической блокировки: все пройдет плохо, обязательно может случиться конфликт. Элемент, подлежащий изменению, блокируется на все время прохождения транзакции до ее успешного завершения. Блокируются все инструкции, входящие в транзакцию. Далее приведем пример скрипта, реализующего пессимистическую блокировку.
@newquantity int
/*полагаем, что со скриптом будут проблемы*/
LOCK product;
SELECT product.name, product.quantity
FROM product
WHERE product.name = ‘Mountain Bike’;
SET newquantity = product.quantity – 20;
UPDATE product
SET product.quantity = newquantity
WHERE product.name = ‘Mountain Bike’;
UNLOCK product;
Инструкции блокировки LOCK и UNLOCK накладываются на таблицу PRODUCT на все время исполнения транзакции, начиная с инструкции на выборку SELECT.
Блокировки – мощный инструмент оптимизации выполнения параллельных транзакций в руках проектировщика запросов. Но при его использовании нельзя забывать об осторожности. В некоторых случаях неправильно настроенная блокировка параллельных транзакций может привести к возникновению аномалии под названием смертельный замок (death lock). Логику аномалии можно увидеть на рис. 7.
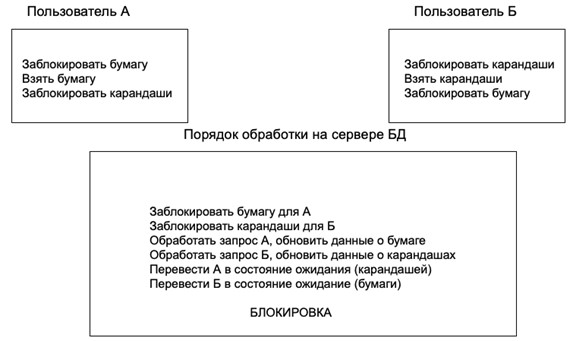
Пользователь А и Пользователь Б изменяют состояние двух объектов, параллельно, в ходе транзакции, блокируя их друг от друга. Это бесконечное состояние ожидания двух параллельных транзакций, которое может быть разрешено средствами СУБД. Также, при составлении скриптов запросов, современные средства СУБД могут предупредить от опасности возникновения этой аномалии блокировки.
***1.4. Тестовые задания для самопроверки.***
1. Управление параллельной обработкой данных выполняется на стороне:
А) администратора данных
Б) администратора СУБД
В) СУБД
Г) сторонней утилитой
2. LUW (Logical Unit of Work), это:
А) SQL инструкция
Б) хранимая процедура
В) транзакция
Г) триггер
Д) ни одно из перечисленного
3. Инструкция COMMIT транзакции…
А) сохраняет результат транзакции
Б) запускает транзакцию на исполнение
В) задает условия выполнения транзакции
Г) откатывает транзакцию в начало
4. Инструкция ROLLBACK транзакции…
А) сохраняет результат транзакции
Б) запускает транзакцию на исполнение
В) задает условия выполнения транзакции
Г) откатывает транзакцию в начало
5. На какой элемент базы данных влияет «изоляция» транзакции?
А) на таблицу
Б) на строки
В) на экземпляр базы данных
Г) на табличное пространство базы данных
6. «Смертельный замок» разрешается на уровне…
А) администратора базы данных
Б) СУБД
В) пользователя
Г) может быть разрешен на любом из перечисленных уровней
7. Какая инструкция не относится к инструкциям управления транзакциями?
А) BEGIN TRANSACTION
Б) REVOKE
В) SAVEPOINT
Г) ROLLBACK
8. Какой из перечисленных видов блокировок устанавливается СУБД по умолчанию?
А) мягкая блокировка
Б) исключительная блокировка
В) неявная блокировка
9. Максимально строгую блокировку элемента БД при выполнении транзакции обеспечивает:
А) сериализуемость
Б) завершенное чтение
В) воспроизводимое чтение
Г) незавершенное чтение
10. Серии действий, выполняющихся на экземпляре БД полностью или не выполняющихся совсем называются:
А) LUW
Б) DML
В) SQL
Г) скрипт