Лекция 8. BigData. noSQL модель данных
**1-ый учебный вопрос: Определение больших данных (BigData) и их свойств. История возникновения термина BigData.**
Большие данные (англ. BigData) - серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала Nature, подготовившему к 3 сентября 2008 года специальный номер журнала с темой «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объёмами данных?», в котором были собраны материалы о феномене взрывного роста объёмов и многообразия обрабатываемых данных и технологических перспективах в парадигме вероятного скачка «от количества к качеству. Несмотря на то, что термин вводился в академической среде, и прежде всего, разбиралась проблема роста и многообразия научных данных, начиная с 2009 года термин широко распространился в деловой прессе, а к 2010 году относят появление первых продуктов и решений, относящихся исключительно и непосредственно к проблеме обработки больших данных. К 2011 году большинство крупнейших поставщиков информационных технологий для организаций в своих деловых стратегиях используют понятие о больших данных, в том числе IBM, Oracle, Microsoft, Hewlett-Packard, EMC.
В 2011 году Gartner отмечает большие данные как тренд номер два в информационно-технологической инфраструктуре. Прогнозируется, что внедрение технологий больших данных наибольшее влияние окажет на информационные технологии в производстве, здравоохранении, торговле, государственном управлении, а также в сферах и отраслях, где регистрируются индивидуальные перемещения ресурсов. С 2013 года большие данные как академический предмет изучаются в появившихся вузовских программах по науке о данных и вычислительным наукам и инженерии.
Источниками такого большого объема данных, который мы характеризуем, как BigData могут быть:
- логи поведения пользователей в интернете;
- GPS-сигналы от автомобилей для транспортной компании;
- данные, снимаемые с датчиков в Большом Адронном Коллайдере;
- оцифрованные книги в Российской Государственной Библиотеке;
- информация о транзакциях всех клиентов банка;
- информация о всех покупках в крупной ритейл сети.
Основные правила (принципы) при работе с BigData:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. Например, если в 2 раза вырос объём данных – в 2 раза увеличили количество hardware в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип отказоустойчивости подразумевает, что компьютеров (серверов) в кластере может быть много. Это означает, что часть этих компьютеров (серверов) будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству компьютеров (серверов). Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их хранят.
**2-ый учебный вопрос: Функция MapReduce, как инструмент работы с BigData. **
MapReduce - модель распределённых вычислений, представленная компанией Google, используемая для параллельных вычислений над очень большими, несколько петабайт, наборами данных в компьютерных кластерах (BigData).
В общем виде, модель MapReduce можно представить следующим образом (рис. 1)
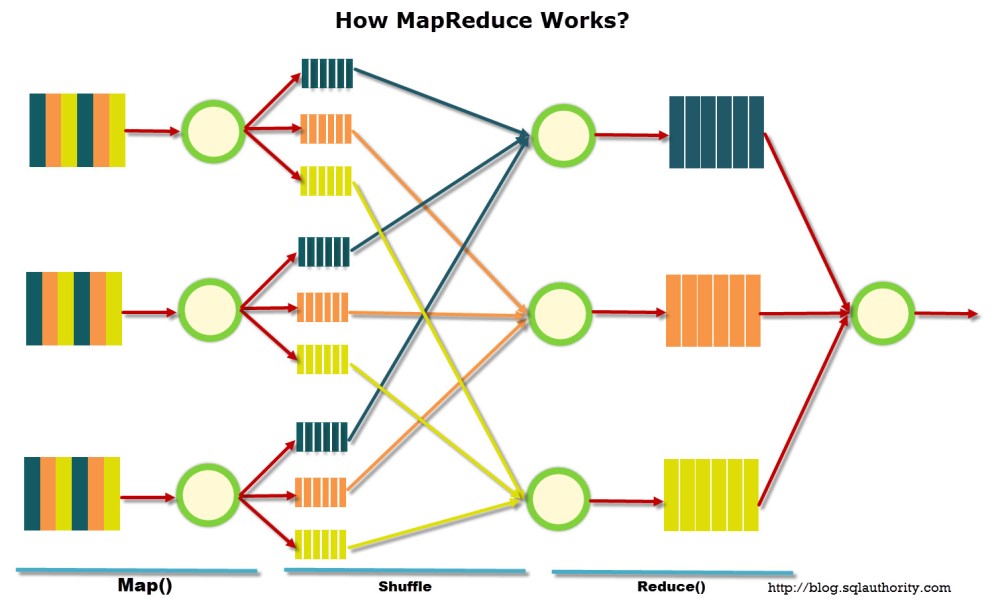
Вся модель состоит из трех основных стадий: Map, Shuffle и Reduce. Первая и последняя задаются пользователем и проводятся по его команде. Процедура Shuffle проводится автоматически и пользователем не контролируется. Для наглядности, покажем конкретный пример работы функции MapReduce. На рис. 2 показаны два варианта решения задачи определения количества (value) проданных книг A, B и C соответственно: SQL выборка и работа функции MapReduce.
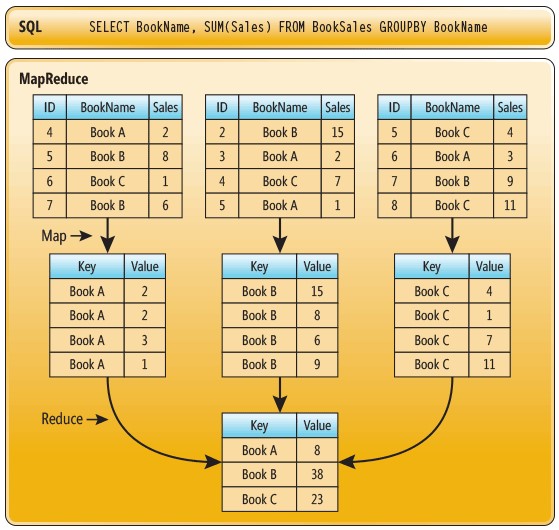
Далее, рассмотрим каждый элемент функции MapReduce отдельно.
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce. На рис. 3 приведен пример выполнения стадии Map (реализован при помощи языка Python) для случая, когда исследователь хочет выяснить, сколько раз в тексте употребляется каждое слово в отдельности.

2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует
одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом
для reduce. Результат функции Map на рис. 3 показан уже после выполнения
shuffle.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии
shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи. Посмотрим, как сделать Reduce для примера, реализованного на рис. 4.

**3-ий учебный вопрос: noSQL модели хранения данных.**
NoSQL (not only SQL, не только SQL), термин, обозначающий ряд подходов, направленных на реализацию хранилищ баз данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с доступом к данным средствами языка SQL.
В NoSQL вместо традиционного реляционного ACID используется набор свойств BASE:
- базовая доступность (basic availability): каждый запрос гарантированно завершается (успешно или безуспешно);
- гибкое состояние (soft state): состояние системы может изменяться со временем, даже без ввода новых данных, для достижения согласования данных;
- согласованность в конечном счёте (eventual consistency) - данные могут быть некоторое время рассогласованы, но приходят к согласованию через некоторое время.
В настоящий момент времени выделяют три наиболее распространенные модели реализации noSQL хранилищ данных:
1. Хранилище “ключ-значение” (Redis, Berkeley DB, Ryak, Amazon).
Хранилища «ключ-значение» является простейшим хранилищем данных, использующим ключ для доступа к значению. Такие хранилища используются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в системах, спроектированных с прицелом на масштабируемость.
В качестве элемента хранения используется пара:
- составной ключ: major keys и minor keys;
- произвольное неструктурированное значение.
Пример реализации данных в хранилище такого типа показан на рис. 5.

2. Хранилище семейств колонок (HBase, Cassandra, Hypertable).
В этом хранилище данные хранятся в виде разреженной матрицы, строки и столбцы которой используются как ключи. Типичным применением этого вида СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности данных.
Индексирование в поисковых системах (веб-индексирование) - процесс добавления сведений (о сайте) роботом поисковой машины в базу данных, впоследствии использующуюся для (полнотекстового) поиска информации на проиндексированных сайтах.
Типы колонок, допустимые в хранилище:
а) Column (колонка) – множество пар ключ-значение (key-value);
б) Column Family (семейство колонок) - содержит множество колонок, у каждой из которых есть название, значение, и временная метка, и на которые ссылаются с помощью ключей строк;
в) Keyspace (пространство ключей) - содержит набор семейств колонок;
г) SuperColumn (суперколонки) - колонки, состоящие из набора подколонок.
Пример реализации данных в хранилище такого типа показан на рис. 6

3. Документо-ориентированная СУБД (CouchDB, mongoDB, Exist).
СУБД, специально предназначенная для хранения иерархических структур данных (документов). В основе ДОСУБД лежат документные хранилища имеющие структуру дерева (иногда леса). Структура дерева начинается с корневого узла и может содержать несколько внутренних и листовых узлов. Листовые узлы содержат данные, которые при добавлении документа заносятся в индексы, что позволяет даже при достаточно сложной структуре находить место (путь) искомых данных.
В отличие от хранилищ типа ключ-значение, выборка по запросу к документному хранилищу может содержать части большого количества документов без полной загрузки этих документов в оперативную память.
Документы могут быть организованы (сгруппированы) в коллекции.
Ключевым принципом реализации этой модели является JSON (JavaScript Object Notation). В качестве значений в JSON используются структуры:
Объект - это неупорядоченное множество пар ключ:значение, заключённое в фигурные
скобки «{ }».
Ключ описывается строкой, между ним и значением стоит символ «:».
Пары ключ-значение отделяются друг от друга запятыми.
Массив (одномерный) - это упорядоченное множество значений. Массив заключается в
квадратные скобки «[ ]». Значения разделяются запятыми.
Значение может быть строкой в двойных кавычках, числом, объектом, массивом, одним из литералов: true, false или null.
Строка - это упорядоченное множество из нуля или более символов юникода, заключенное в двойные кавычки. Символы могут быть указаны с использованием последовательностей, начинающихся с обратной косой черты «\».
Пример структуры данных, описанной с помощью JSON, приведен на рис. 7.
