Лекция 6. Поддержка разработки десктопных приложений баз данных
**1-ый учебный вопрос: Универсальный API доступа к данным ODBC.**
Программный интерфейс доступа к данным, это набор инструкций и драйверов, которые позволяют осуществлять обмен командами между программным приложением и базой данных (СУБД). В настоящее время существуют разные программные интерфейсы, большинство из которых решает узкоспециализированные задачи обеспечения взаимодействия на уровне приложения и базы данных (например ADO, JDBC и т.д.). В данной лекции будет рассмотрен наиболее универсальный на настоящий момент времени программный интерфейс, – ODBC.
ODBC (Open Database Connectivity) - это программный интерфейс доступа к базам данных, разработанный компанией Microsoft на основе спецификаций Call Level Interface (CLI). Стандарт CLI призван унифицировать программное взаимодействие с СУБД, сделать его независимым от поставщика СУБД и программно-аппаратной платформы.
C помощью ODBC прикладные программисты могут разрабатывать приложения для использования одного интерфейса доступа к данным, не беспокоясь о тонкостях взаимодействия с несколькими источниками. Это достигается благодаря тому, что поставщики различных баз данных создают драйверы, реализующие конкретное наполнение стандартных функций из ODBC API с учётом особенностей их продукта. На настоящий момент времени ODBC – наиболее популярное и универсальное средство обеспечения взаимодействия программных приложений и баз данных.
Для работы с ODBC необходимо этот интерфейс сперва интегрировать в операционную систему (сервера, клиентов), а также предварительно настроить. В настоящий момент времени существуют версии ODBC как для ОС MS Windows, так и для UNIX/LINUX систем, таких как Linux, MacOS и т.д.
Наиболее простая установка и настройка интерфейса ODBC происходит для ОС MS Windows (оба продукта разработаны корпорацией Microsoft, что очевидно подразумевает их высокую совместимость). В ОС MS Windows данный интерфейс устанавливается как драйвер, через автоматический установщик. В дальнейшем, настраивается в оболочке программирования для взаимодействия с разными источниками данных.
В ОС Linux и MacOS интерфейс устанавливается через оболочку bash по команде, распаковываясь из пакета. Настраивается через конфигурационные файлы, входящие в комплект поставки и конфигурационные файлы самой ОС. Это связано не только с иной архитектурой данных операционных систем, но и с дополнительными требованиями безопасности к приложениям или драйверам, которые работают в коммуникационных сетях.
В более подробном виде, принцип сборки и настройки интерфейса ODBC будет рассмотрен на лабораторных работах в рамках изучаемой дисциплины. На рис. 29 приведен пример собранного драйвера ODBC для программного приложения баз данных, написанного в языке C++ в оболочке QT. Рассмотрен случай, когда сервер баз данных не содержит HOST-имени, а соединение происходит через IP-адрес.
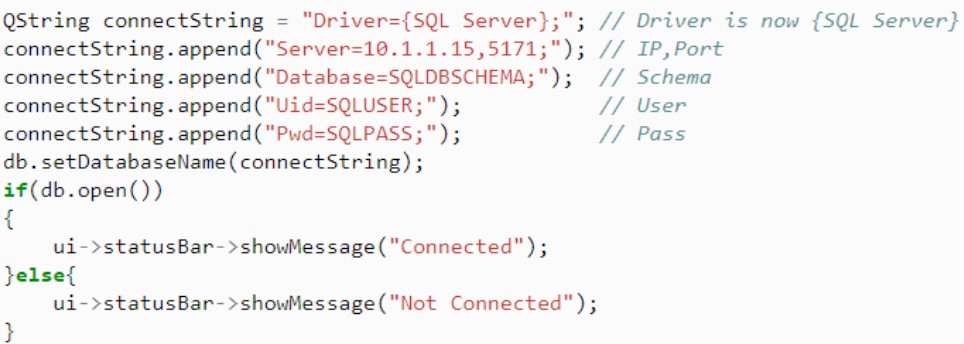
В приведенном на рис. 1 листинге осуществляется не только сборка драйвера, но также через условие if-else реализована обработка исключения “нет соединения с сервером баз данных”. Во время сборки драйвера необходимо указать следующие параметры:
driver - один из драйверов, входящих в интерфейс ODBC, который будет обеспечивать взаимодействие с выбранной СУБД,
IP, Port - ip-адрес сервера баз данных, с которым приложение будет работать, а также порт, через который возможно это взаимодействие; порт указывается после ip через запятую),
schema (db) - название базы данных, находящейся на сервере баз данных, с которой будет работать приложение,
user/pass – информация, аутентифицирующая и авторизующая приложение, как одного из пользователей базы данных.
После компиляции программного кода приложения, в случае прохождения проверки пользователя и установления соединения с сервером, программное приложение сможет передавать команды напрямую СУБД базы данных и получать оттуда результатные данные.
Приведем еще ряд актуальных программных интерфейсов доступа к данным.
OLE DB (Object Linking and Embedding, Database) - набор интерфейсов, которые позволяют приложениям унифицировано работать с данными разных источников и хранилищ информации.
ADO (ActiveX Data Objects) — интерфейс программирования приложений для доступа к данным. ADO позволяет представлять данные из разнообразных источников (реляционных баз данных, текстовых файлов и т. д.) в объектно-ориентированном виде.
JDBC (Java DataBase Connectivity) - платформенно независимый промышленный стандарт взаимодействия Java-приложений с различными СУБД, реализованный в виде пакета java.sql, входящего в состав Java SE.
**2-ый учебный вопрос: Встроенный SQL в приложениях баз данных.**
Следующим этапом после установления подключения к базе данных является программирования взаимодействия с массивами данных на сервере. Программное приложение должно иметь возможность передать инструкцию на запись, выборку, модификацию данных СУБД, а также – получить и выдать в удобном виде результатные выборки из базы данных.
Однако, в своем естественном виде инструкции SQL не могут быть встроены в язык программирования, на котором осуществляется разработка программного средства. Это обусловлено природой данных в SQL запросе, которые представляют собой набор записей, который не привязан к физическому количеству записей в таблице. В традиционных языках программирования такой структуры данных не существует, что делает использование SQL внутри программного приложения невозможным.
С целью реализации взаимодействия десктопного приложения (в первую очередь речь идет о приложениях, написанных в языке С, C++ или Java), существует диалект языка SQL – embedded SQL или встроенный SQL. Отдельной вариацией embedded SQL является диалект языка SQL – SQLJ (подмножество стандарта SQL, направленное на объединение преимуществ синтаксиса языков SQL и Java ради удобства реализации бизнес-логики и работы с данными).
Принцип работы embedded SQL внутри программного приложения состоит из двух этапов.
1. Препроцессор конвертирует команду SQL в специальный API вызов.
2. Затем обычный компилятор, в обычном режиме компилирует код программы.
Основные конструкции embedded SQL:
Соединение с БД: EXEC SQL CONNECT;
Объявление переменных: EXEC SQL BEGIN (END) DECLARE SECTION; Выражения языка: EXEC SQL Statement;
Ниже в виде листинга кода показан пример объявления переменных с помощью встроенного SQL.
EXEC SQL BEGIN DECLARE SECTION
char c_sname[20];
long c_sid;
short c_rating;
float c_age;
EXEC SQL END DECLARE SECTION
Обратите внимание на последовательность объявления переменных. В отличие от классического SQL, для каждой пары сперва объявляется тип данных (в приведенном примере это char, long, short, float), а затем – название самой переменной. Секция объявления переменных открывается и закрывается специальными командами BEGIN и END.
Фрагменты динамического SQL и SQLJ с реализацией логики приложения с краткими комментариями приведены ниже.
Пример листинга встроенного SQL (язык С).
char SQLSTATE[6]; //переменная для отслеживания EoF (end of file)
EXEC SQL BEGIN DECLARE SECTION //объявляем переменные для работы с данными
char c_sname[20];
short c_minrating;
float c_age;
EXEC SQL END DECLARE SECTION
c_minrating = random(); //значением этой переменной станет произвольное значение типа short
EXEC SQL DECLARE sinfo CURSOR FOR //формирование курсора (массива данных) для обработки на стороне приложения
SELECT S.sname, S.age FROM Sailors S
WHERE S.rating > :c_minrating ORDER BY S.sname; //классическая SQL инструкция на выборку данных, переменные с : перед названием – это переменные, созданные в приложении.
do { EXEC SQL FETCH sinfo INTO :c_sname, :c_age; printf
(“%s is %d years old\n”, c_sname, c_age);}
while (SQLSTATE != ‘02000’); //построчная (FETCH) выгрузка в
программу содержимого курсора sinfo в удобном для чтения виде. 02000 – код ошибки EoF (end of file)
EXEC SQL CLOSE sinfo; //очистка курсора sinfo
Пример листинга встроенного SQLJ (язык Java).
int sid; String name; Int rating; //задаем переменные
#sql iterator Sailors(Int sid, String name, Int rating); //задаем итератор
Sailors sailors;
…предполагаем, что приложение устанавливает рейтинг…
#sailors = {SELECT sid, sname INTO :sid, :name FROM Sailors WHERE rating = :rating }; //возвращаем результаты
while (sailors.next()) { System.out.println(sailors.sid + “ “ + sailors.sname)); } sailors.close(); //вывод результатов на экран через приложение
**3-ий учебный вопрос: Использование курсоров в встроенном SQL.**
Приложения, особенно интерактивные, не всегда эффективно работают с результирующим набором как с единым целым. Им нужен инструмент-посредник, позволяющий обрабатывать массив данных построчно. Курсоры являются расширением результирующих наборов, которые предоставляют такой механизм.
В зависимости от архитектуры приложения баз данных и желаемого распределения нагрузки по обработке данных выделяются три основных способа реализации курсоров.
Курсоры в синтаксисе языка (наречия) SQL. Используются в скриптах, хранимых процедурах, триггерах. Реализуются на сервере и управляются инструкциями, отправляемыми от клиента серверу.
Серверные курсоры интерфейса прикладного программирования (API). Курсоры API поддерживают функции курсоров в ODBC. Всякий раз, когда клиентское приложение вызывает функцию курсора API, драйвер ODBC для собственного клиента СУБД передает требование на сервер для выполнения действия в отношении серверного курсора API.
Клиентские курсоры. Клиентские курсоры реализуются внутренне драйвером ODBC для собственного клиента СУБД. Клиентские курсоры реализуются посредством кэширования всех строк результирующего набора на клиенте. Каждый раз, когда клиентское приложение вызывает функцию курсора API, драйвер ODBC для собственного клиента СУБД выполняет операцию курсора на строках результирующего набора, кэшированных на клиенте.
Помимо основной функции курсора, как инструмента формирования массивов данных для передачи в приложение базы данных, курсоры решают следующие задачи:
- получение выборок из отдельных строк результирующего набора;
- получение необходимого количества строк от текущей позиции в результирующем наборе;
- отслеживание и демонстрация изменения данных в строках в текущей позиции результирующего набора;
- поддержка (в зависимости от типа выбранного курсора) разных уровни видимости изменений, сделанных другими пользователями для данных, представленных в результирующем наборе.
В зависимости от решаемой задачи, программист может сформировать однонаправленный, статический или динамический курсор (тут и далее – речь про курсоры ms sql server).
Однонаправленный курсор указывается как FORWARD_ONLY. Он также называется курсором firehose и поддерживает только получение строк последовательно, от начала до конца курсора. Строки нельзя получить из базы данных, пока они не будут выбраны.
Так как такой курсор не может быть прокручен назад, большинство изменений, сделанных в строках базы данных после извлечения сроки, не видны. Если значение, использованное для определения положения строки в результирующем наборе, модифицируется, например в случае обновления столбца, входящего в кластеризованный индекс, то значение видимо через курсор.
Полный результирующий набор статического курсора создается в базе данных tempdb при открытии курсора. Статический курсор всегда отображает результирующий набор точно в том виде, в котором он был при открытии курсора. Статическими курсорами обнаруживаются лишь некоторые изменения или не обнаруживаются вовсе, но при этом в процессе прокрутки такие курсоры потребляют сравнительно мало ресурсов.
Курсор не отражает изменения в базе данных, влияющие на вхождение в результирующий набор или изменяющие значения в столбцах строк, составляющих набор строк. Статический курсор не отображает новые строки, вставленные в базу данных после открытия курсора, даже если они соответствуют критериям поиска инструкции SELECT курсора.
Статический курсор продолжает отображать строки, удаленные из базы данных после открытия курсора.
Статический курсор всегда доступен только для чтения.
Динамические курсоры отражают все изменения строк в результирующем наборе при прокрутке курсора. Значения типа данных, порядок и членство строк в результирующем наборе могут меняться для каждой выборки. Все инструкции UPDATE, INSERT, DELETE, выполняемые пользователями, видимы посредством курсора. Обновления видимы сразу, если они сделаны посредством курсора с помощью функции API или специального предложения SQL.
Обновления, сделанные вне курсора, не видны до момента фиксации, если только уровень изоляции транзакций с курсорами не имеет значение READ UNCOMMITTED.
Далее будет приведен общий принцип обработки курсоров, сперва в месте его создания, а затем в логике приложения.
1. Связать курсор с результирующим набором инструкции и задать его характеристики (например возможность обновления строк).
2. Выполнить инструкцию для заполнения курсора.
3. Получить в курсор необходимые строки. Операция получения в курсор одной и более строк называется выборкой. Выполнение серии выборок для получения строк в прямом или обратном направлении называется прокруткой.
4. При необходимости выполнить операции изменения (обновления или удаления) строки в текущей позиции курсора.
5.Закрыть курсор.
Пример использования курсора показан выше (рис. 1), в листинге встроенного SQL.
**Вопросы для самостоятельного изучения по итогам лекции.**
1. Перечислите типы курсоров Oracle.
2. Поясните смысл использования курсорной инструкции FETCH.
Напишите простой синтаксис этой инструкции.
3. Напишите хранимую процедуру для заполнения столбца inStock таблицы WH произвольными значениями. Исходная точка – столбец заполнен значениями NULL. Всего имеется 37 строк.
4. В чем принципиальное отличие OLE DB от ODBC драйвера?
Тестовые задания для самопроверки.
1. На каком уровне происходит упорядочивание кортежей в реляционной модели данных:
А) на физическом
Б) на физическом и операционном
В) на операционном
2. Учитываются ли скобки в операциях реляционной алгебры?
А) да, учитываются
Б) нет, не учитываются
В) только в теоретико-множественных операциях реляционной алгебры
3. Какая из перечисленных моделей данных не использует инструкции языка SQL?
А) документная модель хранения
Б) столбцовая БД
В) хранилище данных
4. Как называется курсор без возможности прокрутки?
А) статический;
Б) однонаправленный;
В) динамический.
5. Выбрать необходимые данные из одной или нескольких взаимосвязанных таблиц, отобрать нужные поля, произвести вычисления и получить результат в виде новой таблицы можно с помощью …
А) запроса
Б) схемы данных
В) главной кнопочной формы
Г) составной формы
6. Взаимодействие прикладных программ с большей частью СУБД осуществляется при помощи:
А) русского языка
Б) языка программирования С++
В) прикладное ПО не взаимодействует с СУБД
Г) языка структурированных запросов
7. Нормализация это…
А) разделение единой таблицы базы данных на несколько, для дальнейшего связывания таблиц
Б) изменение структуры базы данных с целью устранения избыточности и нарушения целостности
В) добавление, изменение и удаление записей и таблицу
8. Что такое хранимая процедура?
А) процедура, хранящаяся в БД
Б) скомпилированный набор операторов Transact-SQL
В) процедура, переданная из другой системы
9. Триггеры создаются для:
А) корректировки БД
Б) согласования логики связанных данных в различных таблицах
В) поддержки целостности БД
10. XML это:
А) язык разметки, обладающий собственным синтаксисом
Б) утилита экспорта/импорта данных в/из СУБД
В) язык программирования
11. Средство визуализации информации, позволяющее осуществить выдачу данных на устройство вывода или передачу по каналам связи, – это …
А) отчет
Б) форма
В) шаблон
Г) заставка