Лекция 4. Аспекты реализации проекта хранилища данных.
**2.1. Проект разработки хранилища данных. Команда проекта разработки.**
Проект разработки хранилища данных, с точки зрения методологии, мало чем отличается от проектов разработки программного обеспечения информационных систем и информационных технологий. В зависимости от поставленных в техническом задании, проект может реализовываться как в классическом, последовательном виде, так и в «гибких» сценариях разработки. Этапы жизненного цикла хранилища данных также, в целом, схожи с жизненным циклом программного продукта и показаны на рис. 8.
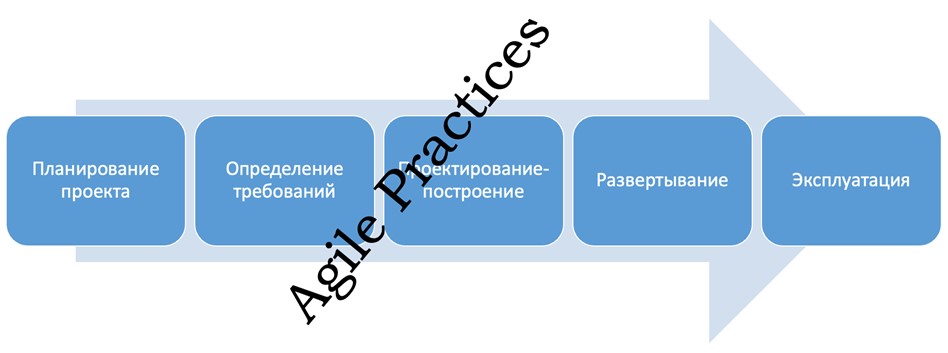
Выделяют пять основных стадий жизненного цикла, за реализацию которых отвечает команда проекта: планирование, постановка задачи, проектирование и построение хранилища, развертывание и эксплуатация, вплоть до вывода хранилища данных из эксплуатации.
На этапе планирования проекта определяется предметная область проектирования, изучению подлежит объект исследования (организация, для которой будет разрабатываться хранилище данных). Исследование целесообразно проводить инженерам, входящим в группу разработки, ведь его результатом, как правило, является набор формальных требований к проекту.
На этапе определения требований к проекту происходит конвертация неформальных требований, собранных в ходе изучения объекта исследования в формальные требования, которые удобно использовать как KPI при оценке результатов проекта, так и как исчерпывающее, однозначное, максимально подробное руководство для проектировщиков. Артефактом этого этапа является техническое задание на проектирование хранилища данных.
В ходе проектирования и построения хранилища, команда разработчиков сперва создает и максимально оптимизирует модель будущего хранилища данных, после чего последовательно превращает ее сперва в скрипт языка программирования, а затем – готовит к развертыванию на тестовых мощностях заказчика проекта. В ходе реализации этого большого и значимого этапа, как и в случае с программным обеспечением, создается сопроводительная документация, вспомогательные эскизы интерфейсов и листинги программного кода. Также осуществляется модульное тестирование компонентов хранилища (хранимых процедур, процедур ETL), если это необходимо.
Готовое хранилище разворачивается на мощностях заказчика в ходе релиза или развертывания. После подготовки соответствующего помещения, сборки и настройки «железа», установки необходимого программного обеспечения, включая операционные системы на серверы, происходит выполнение листингов программного кода и создание рабочей физической модели хранилища данных. Оно заполняется операционными или тестовыми данными и проходит пуско-наладочные испытания.
Стадия эксплуатации, в первую очередь, связана с гарантийным и послегарантийным обслуживанием компонентов хранилища данных. Также, в ходе этого самого длительного этапа жизненного цикла хранилище данных оно проходит постоянную модернизацию, логично завершая этот цикл архивированием и переносом аккумулированных данных и выводом действующей модели хранилища из эксплуатации.
Одной из наиболее важных задач, которые решаются в ходе планирования проекта хранилища данных является определение участников проекта и их компетенций, которые способны решить все поставленные перед группой проекта задачи. Данная задача осложняется тем, что основная масса профессиональных проектировщиков данных в ходе своей профессиональной деятельности имеет дело с традиционной OLTP моделью хранения данных (реляционные базы данных) и когда компания принимает решение о переходе к OLAP модели хранилища данных обязательно встает вопрос профессиональной квалификации имеющихся ИТ-специалистов. Необходимо или переучивать имеющихся, или искать на рынке труда сформировавшихся профессионалов.
Далее, определим возможные роли проекта хранилища данных и кратко опишем набор трудовые задачи каждой из ролей.
Исполнительный спонсор (директор проекта, executive sponsor), лицо, принимающее решения в ходе реализации проекта. К числу его ключевых обязанностей относится поддержка и отстаивание интересов проектной команды у заказчика, финансирующего проект. Разрешение спорных ситуаций, возникающих в ходе реализации проекта, - также в компетенции этого специалиста. Модельные навыки специалиста: хорошее знание предметной области проекта, энтузиазм и высокая психологическая устойчивость.
Проектный менеджер (project manager) – ответственный за ход реализации проекта, на которого возложены обязанности мониторинга хода его выполнения. В его компетенции находится формирование распоряжений и контроль их выполнения. Модельные навыки специалиста: навыки тайм-менеджмента, знание актуальных методологий разработки программного обеспечения, глубокий опыт управления проектами.
Менеджер по связям с пользователями (user liaison manager) – всесторонняя координация с конечными пользователями хранилища данных в ходе всего проекта разработки с возможностью внесения корректировок в проект. Модельные навыки: уважение в среде конечных пользователей программного продукта, высокий уровень организационных навыков, понимание точки зрения конечного пользователя продукта.
Ведущий архитектор хранилища (lead architect) – рассмотрение разных вариантов реализации хранилища данных, учитывая требования конкретного проекта разработки и выбор оптимальной архитектуры. Его главной задачей является составление максимально подробного и понятного архитектурного проекта хранилища данных (модель хранилища на верхнем уровне абстракции) в виде документа. Модельные навыки: навык масштабирования моделей проекта от верхнего уровня абстракции до максимально подробной декомпозиции, хорошо развитые аналитические навыки, «евангелизм» (высокий уровень знания современных информационных технологий и устоявшееся собственное мнение по их применению).
Специалист по инфраструктуре хранилища (infrastructure specialist) – проектирование всей необходимой для развертывания хранилища данных инфраструктуры (в которую входит «серверное и клиентское железо», операционные системы и сопутствующее программное обеспечение, сетевое оборудование и пр.). Этот же специалист руководит процессом релиза артефакта хранилища данных на мощностях заказчика проекта. Модельные навыки: хорошее знание актуального «железа» на рынке, высокий уровень знаний о принципах работы современных операционных систем и системных приложений, обширный опыт работы с серверным оборудованием и программным обеспечением в качестве пользователя.
Бизнес-аналитик (business analyst). Основной задачей является изучение бизнес-процессов на стороне заказчика и интерпретация их в более формальную модель для проекта. Им должны быть сформулированы четкие бизнес-правила и бизнес-ограничения, впоследствии закладываемые в логику работы хранилища данных, утилит ETL, итоговых витрин данных. Модельные навыки: большой опыт взаимодействия с конечными пользователями в разных предметных областях, большой опыт бизнес-аналитики и глубокое знание основных нотаций описания бизнес-процессов и бизнес-логики организаций.
Инженер данных (data modeler) – специалист по логическим моделям хранилища данных. Его основная задача – проектирование таблиц фактов и наборов измерений для решения поставленных в техническом задании задач. Модельные навыки: опыт аналитика данных, большой опыт работы как с OLAP, так и с OLTP моделями баз и хранилищ данных. Навыки построения распределенных (кластеры) баз данных.
Администратор хранилища данных (data warehouse administrator) – основная роль в ходе эксплуатации хранилища данных. В роли советника участвует в ходе реализации проекта хранилища данных. Обеспечивает бесперебойную работу хранилища данных в ходе эксплуатации, организовывает мероприятия, связанные с обеспечением безопасности данных. Модельные навыки: опыт администрирования хранилищ и баз данных, глубокие знания элементов физической модели баз данных и хранилищ данных.
Специалист по трансформации данных (data transformation specialist) – ответственный за сборку и настройку ETL (extract, transform, load) процедур для хранилища данных и всех их производных. Модельные навыки: глубокое понимание типовых структур данных и потоков данных, понимание принципов работы разных источников информации, большой опыт практических навыков работы в программном обеспечении, связанным с ETL процессами.
Специалист по качеству данных (quality assurance analyst) – разработка и имплементация процедур, связанных с очисткой и верификацией данных, которые находятся непосредственно в хранилище данных. Модельные навыки: опыт мероприятий, связанных с повышением качества данных, глубокое понимание принципов работы источников информации и потоков данных.
Координатор по тестированию (testing coordinator) - разработка и проведение мероприятий по тестированию в ходе разработки и в ходе релиза хранилища данных. Тестированию, помимо самого хранилища подвергаются программы, системы и сопутствующие инструменты хранилища данных. Модельные навыки: знание актуальных стандартов и методов тестирования, опыт работы с программным обеспечением тестирования, понимание принципов работы «входов и выходов» хранилища данных, навыки программирования.
Специалист по пользовательским приложениям (end-user applications specialist). Основная задача – это проверка и подтверждение data usability (применимости массивов данных хранилища) в конечных приложениях пользователя. Проще говоря, это проверка того – поступают ли необходимые данные из хранилища в конечное приложения пользователя и годятся ли они в конечном виде для проведения аналитических исследований. Модельные навыки: большой опыт работы в конечных приложениях пользователя, связанных с аналитическими исследованиями.
Разработчик (программист, development programmer) занимается разработкой приложений и утилит, которые используются в процессе проектирования и создания программного обеспечения хранилищ данных. Отдельно отметим, что это не пользовательские приложения, а приложения, которые будут использоваться группой разработки в ходе реализации проекта. Модельные навыки: опыт программирования системных утилит и приложений, опыт проектирования баз данных.
Управляющий программы обучения (lead trainer) координирует программы обучения конечных пользователей хранилища данных. Модельные навыки: навыки педагогики и обучения IT-специалистов, хорошо развитые организаторские навыки, расширенные познания в человеческой психологии, опыт разработки программ и курсов обучения.
**3.2.2. Ключевые точки успеха проекта хранилища данных. Тупиковые сценарии проектов.**
Далее будут рассмотрены особенности успешных и неуспешных проектов хранилищ данных. Эти закономерности удалось выявить и оформить в виде практик вследствие того, что проекты хранилищ данных, это сравнительно редкие проекты, и практически все случаи их реализации известны. Суммируя результаты работы проектных групп со всего мира, удалось выявить некоторые закономерности, которые, несомненно, будут полезны руководителям последующих проектов.
Начнем с перечисления и описания ключевых точек успеха проекта хранилища данных. Без должного внимания этим процессам и показателям проекта, группа проекта существенно увеличивает риск недостаточного качества проекта, а, в некоторых случаях и его неудачи.
Масштабирование и правильная оценка потенциала роста хранилища данных. Необходимо четко понимать, что после релиза, количество пользователей хранилища и количество запросов к нему будет расти в геометрической прогрессии, поэтому, при создании первичной модели оценки нагрузки на серверы хранилища нужно оценивать не текущие параметры нагрузки, а планируемые, причем с перспективой на среднесрочный период эксплуатации.
Реалистичные ожидания. В первую очередь, это касается заказчиков проекта хранилища данных. В краткосрочной перспективе эксплуатации хранилища данных никаких серьезных изменений в качестве бизнес-процессов, которые поддерживаются этим хранилищем вероятнее всего не будет. Также вероятно, что сотрудники сперва весьма неохотно будут использовать потенциал хранилища данных в своей операционной работе, больше доверяя традиционных средствам хранения и обработки данных Отдачи от внедрения следует ожидать в среднесрочной и долгосрочной перспективе.
Внимание к моделированию измерений. Вам уже известно, что изменения в реляционных базах данных в ходе их эксплуатации «стоят» очень дорого с точки зрения трудозатрат, времени и рисков. Для страховки от этого риска следует больше внимания уделять построению логических моделей данных на этапе их проектирования. Учитывая более комплексную природу хранилищ данных разумно предположить, что изменения в ходе эксплуатации будут обходиться организации еще дороже. Предварительное моделирование измерений и определение лучшего варианта из нескольких по таблицам фактов на этапе проектирования позволит существенно сократить этот риск.
Анализ внешних потоков данных. Хранилище является агрегатной базой данных для хранения данных, приходящих из принципиально разных по своей структуре источников, – это и плоские файлы, и данные из базы данных организации и данные из баз данных контрагентов, и данные, как результат бенчмаркетинговых исследований и т.д... Тщательное изучение всех возможных источников данных существенно упростит управление ETL-процессами в ходе загрузки данных и настройку утилит для очистки данных, уже попавших в хранилище.
Внимание обучению конечных пользователей и администраторов. Если до реализации проекта хранилища данных, организация отдавала предпочтение традиционным способам хранения данных (реляционные базы данных), то очевидно, что у конечных пользователей и администраторов (даже самых опытных), на начальном этапе использования хранилища будут проблемы на уровне языка программирования запросов к хранилищу и даже конечных программных средств, которые будут работать с данными из этого хранилища. При формировании плана обучения обязательно следует обратить внимание и на опытных пользователей аналитических приложений и специалистов по базам данных.
Согласованная бизнес-оценка используемого для хранилища стека технологий. Хранилище данных не может существовать само по себе. Для его нормального функционирования потребуется множество программных продуктов, которые способны обеспечить передачу, подготовку, очистку данных, выгрузки из хранилища, а также проведение мероприятий, связанных с аналитической обработкой полученной информации. Все эти технологии, вместе с самим хранилищем должны оцениваться комплексно (как неотъемлемая часть проекта), как одно большое решение в рамках проекта хранилища данных.
Высокая степень вовлеченности конечного пользователя в проект разработки хранилища. Это позволит добиться более лояльного отношения пользователей к конечному продукту и снизить промежуток времени, до принятия готового хранилища данных в операционную работу. Также, постоянный контакт с конечными пользователями чрезвычайно важен для хорошего результата не только в реализации функциональных требований к проекту, но и высоких эргономических, нефункциональных показателей.
Сперва – архитектура, затем – методология и в конце – инструменты. Это оптимальная последовательность решения задач на начальном этапе планирования проекта хранилища данных.
Проект хранилища данных должен включать в себя все этапы жизненного цикла продукта, включая этап его эксплуатации на длительный горизонт планирования. Хранилище постоянно должно находиться в состоянии оптимизации, настройки, модернизации. Только так можно максимально продлить срок эффективной эксплуатации дорогостоящего хранилища данных.
Смена фокуса на проектирование запросов. В отличие от реляционной базы данных, на этапе программирования элементов хранилища внимание уделяется не транзакциям (они будут выполняться особым, отличным от реляционного способом), а запросам. Это связано с тем, что зачастую аналитические запросы, ввиду своих особенностей, не повторяются (аналитикам постоянно надо искать новые тенденции, тренды, закономерности) и единственные актуальные транзакции для хранилища данных связаны с добавлением в него новых массивов данных.
Критическое отношение к источникам данных. Не должна стоять задача: «забрать в хранилище все возможные данные». Это приведет лишь к мусорной помойке, вместо полезного элемента IT-архитектуры предприятия. Загружаться должны только действительно нужные данные, преимущественно из надежных источников и потоков.
Любые существенные отклонения от ключевых точек успеха приводят к проблемам в ходе реализации проекта хранилища данных, а в дальнейшем – к существенным неудобствам и затратам в ходе его эксплуатации. Типовые случаи тупиковых сценариев проектов хранилищ данных показаны на рис. 9.
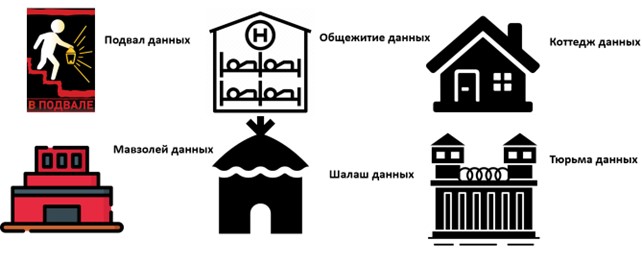
Рассмотрим приведенные сценарии подробнее.
Подвал данных. В этом случае команда проекта недостаточно внимательно относится к исследованию источников данных, предлагаемых заказчиком. Как правило, принимается решение включить все доступные источники. В итоге, группа разработки сталкивается с серьезными проблема в ходе разработки ETL-процедур, в попытках синхронизировать изначально плохо согласованные друг с другом, а зачастую и недостоверные данные. Проблемы, связанные с источниками, сперва приводят к тому, что данные в хранилище имеют весьма плохое для проведения аналитики качество, в результате чего конечных пользователь предпочитает ими никогда не пользоваться, «запирая» их в подвал, в котором никто никогда не бывает.
Общежитие данных. На этапе планирования решено сэкономить и в качестве базовой модели для построения хранилища будет использована legacy (прошлая, заменяемая) физическая модель базы данных. Группа проекта сознательно пропускает этап сбора требований и в итоге, логично приходит к той же модели, с ее недостатками, что были и в legacy модели хранения данных.
Коттедж данных. В ходе разработки, группа проекта уделяет внимание созданию постоянных витрин данных на основании запросов от конечных пользователей-аналитиков. В итоге, выход хранилища представляет собой строго определённый тематикой исследований набор витрин данных. При это сильно фрагментируются данные, находящиеся в хранилище, что существенно затрудняет решение задач, выходящих за пределы ожидаемых при постановке задач на проектирование хранилища массивов данных.
Мавзолей данных. На этапе проектирования хранилища заказчик так и не определился, в рамках каких процессов будет использоваться хранилище данных. «Это современная технология, она обязательно пригодится», - думал заказчик. В результате, после релиза получается ситуация, когда аналитики продолжают пользоваться традиционными источниками данных для проведения исследований и совершенно не совершают попыток перейти к взаимодействию с новым хранилищем данных. В итоге получается дорогое и бессмысленное IT-решение в дополнительную нагрузку ложится на организацию.
Шалаш данных. Выполнено сотрудниками, не имеющими ни практических, ни теоретических знаний о базовых принципах построений хранилищ данных, с полным игнорированием ключевых точек успеха проекта. В итоге получается забагованная, никому не нужная свалка несогласованных данных.
Тюрьма данных. В целом хорошо спроектированное хранилище данных, но, в ходе проекта, команда проекта редко взаимодействовала с конечными пользователями. В итоге пользователи, испытывая проблемы с затрудненным и неудобным доступом к данным отказываются от использования хранилища в пользу традиционных способов работы с данными.
**3.2.3. Трехмерная модель хранения данных. Понятие Informational Package (информационный пакет)**
Конечная цель функционирования хранилища данных – хранение, сбор и передача данных в службы аналитики компании. Именно особенности подготовки данных для проведения процедур статистического, математического анализа, машинного обучения и пр., и определяют архитектуру и характер эксплуатации хранилища. Большинство даже самых простых регулярных аналитических исследований требуют более чем двухмерную модель визуализации результата (редко когда можно обойтись двумерным линейным графиком или гистограммой в аналитике и прогнозировании результатов бизнеса организации). Самой распространенной аналитической моделью для бизнес-исследований является так называемое трехмерное бизнес-измерение. По своей сути – это куб, содержащий внутри себя множество значений, по периметру которого на ребрах находятся различные возможные для имеющихся значений измерения (шкалы). Для лучшего понимания, приведем простой пример. «Золотой стандарт» базовой бизнес-аналитики – это анализ продаж по трем измерениям: что продавалось (продукт), какой срок продаж интересует (время) и место, где осуществлялись продажи (пространство или география). Структура куба для этого исследования с примерами приведена на рис. 10.
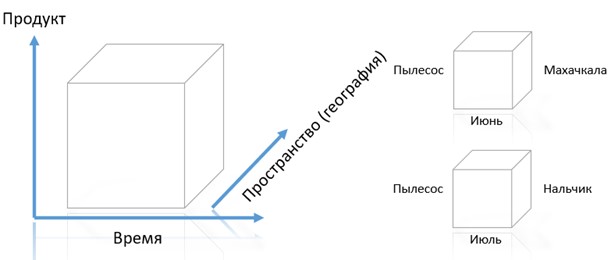
Конкретные значения, определенные по ребрам куба в ходе процесса анализа в результате, формируют срез данных, который является ответом на вопрос задачи. Так, в приведенным примере исследователь получит срез данных по июньским продажам пылесосов в Махачкале и по продажам тех же пылесосов в июле, но уже в Нальчике.
Очевидно, не всегда задачи, стоящие перед аналитиками данных ограничены всего тремя измерениями (ребрами куба). Для их решения требуется построение большего количества измерений (векторов). Модель, которая получается в итоге, называется гиперкуб (многовекторные измерения). Каждый сформированный гиперкуб дает исследователю возможность получать срезы данных, как комбинацию разных интересующих его факторов в любой последовательности, используя при этом одно и то же пространство данных гиперкуба. На рис. 11 показаны несколько примеров гиперкубов для разных направлений хозяйственной деятельности организации.
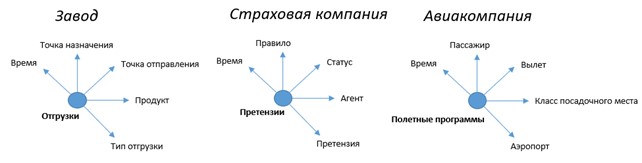
Рассмотрим варианты гиперкубов из приведенного примера. Жирным шрифтом выделены данные из внутреннего пространства куба (как правило, это математически значимые значения, получаемые в ходе основной операционной деятельности организации). Простыми словами – это количественные данные по отгрузками для завода, количественные данные по претензиям клиентов для страховой компании и количественные данные по полетным программам для авиакомпании. Обычным шрифтом в примерах показаны измерения, которые могут использоваться в качестве ребер гиперкуба при различных аналитических исследованиях. Так, аналитик может, наложив на пространство данных значения измерений Время и Продукт, получить срез данных по продуктам, отгруженным со склада готовой продукции завода. Отметим, что непосредственно прогнозирование не является задачей для хранилища данных и после формирования нужного среза данных, он отправляется в соответствующие программные средства аналитики (SPSS, Data Lens, R Studio и др.).
Пространство значений гиперкуба называется измеряемыми фактами, а пространства измерений, их окружающие называют измерениями. Учитывая тот факт, что измеряемых фактов может быть несколько (для завода, например, это не только отгрузки, но и передача на хранение, поставка материалов для производства, данные о производстве и т.д.), конечная модель хранилища данных может быть весьма комплексной и запутанной. Для того, чтобы существенно упростить процесс моделирования хранилища на стартовом этапе проекта его разработки, применяются таблицы с неполностью детерминированными требованиями (неформализованные спецификации), которые называются информационные пакеты (informational package). Эти пакеты представляют собой модель, определяющую значимые факты и измерения для планируемых к реализации в хранилище гиперкубов в компактном табличном виде. Заголовком информационного пакета является перечисление требуемых фактов, столбцы информационного пакета – названия участвующих измерений, а значения столбцов, – возможные свойства измерений. Шаблон такой таблицы приведен на рис. 12.
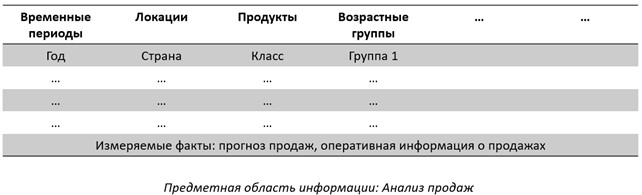
Перечисление планируемых к сбору и хранению фактов обычно оформляется в нижней части пакета (прогноз продаж, данные о продажах и т.д.). Столбцы Локации, Продукты, Продавцы, Покупатели, Контрагенты и др. формируют структуру измерений, которые будут окружать факты и станут дискриминаторами в ходе процедур извлечения срезов данных для анализа из хранилища. Каждое измерение – это таблица, столбцы которой, это значения столбцов из информационного пакета. Например, столбцами измерения Временные периоды могут стать Год, Квартал, Месяц, Неделя, День и т.д...
Далее, приведем два развернутых примера информационных пакетов, созданных для изучения продаж автопроизводителя (рис. 13) и заселенности номеров отеля (рис. 14).
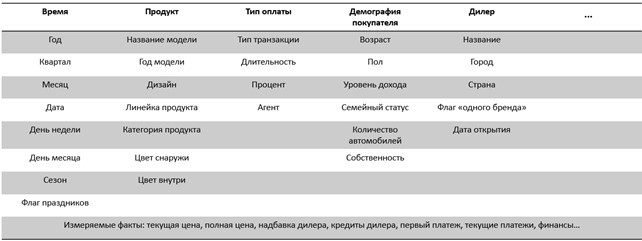
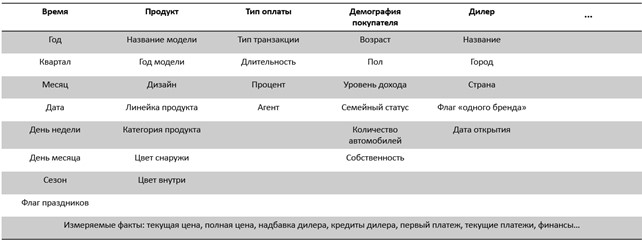
Совокупность информационных пакетов по всем возможным «темам» аналитики, на основании срезов, - своего рода техническое задание на проектирование логической модели хранилища данных. О принципах построения непосредственно хранилища будет рассказано в следующей главе.
** 2.4. Вопросы для самостоятельного изучения по теме.**
(кейс) Вы – аналитик проектной команды, задачей которой является создание хранилища данных для некоторой компании (например, определенная предметная область исследования диссертации). Составьте один или несколько Informational package для вашей темы (рис. 12, 13, 14).
Отчет оформить в шаблоне документа (форма документа доступна в группе предмета и будет предложена преподавателем отдельно).
**2.5. Тестовые задания для самопроверки.**
1. Специалист команды проекта хранилища данных, ответственный за построение ETL пайплайнов, это:
А) ведущий архитектор
Б) инженер данных
В) специалист по трансформации данных
Г) специалист по качеству данных
Д) разработчик
2. Специалист команды проекта хранилища данных, ответственный за проверку данных в хранилище (верификацию):
А) ведущий архитектор
Б) инженер данных
В) специалист по трансформации данных
Г) специалист по качеству данных
Д) разработчик
3. В тем проблема тупикового сценария хранилища данных «Подвал данных»:
А) качественные данные не попадают в хранилище
Б) данные в хранилище плохо структурированы
В) данные в хранилище бесполезны для конечного пользователя
Г) доступ к данным со стороны конечного пользователя затруднен
4. В тем проблема тупикового сценария хранилища данных «Мавзолей данных»:
А) качественные данные не попадают в хранилище
Б) данные в хранилище плохо структурированы
В) данные в хранилище бесполезны для конечного пользователя
Г) доступ к данным со стороны конечного пользователя затруднен
5. В тем проблема тупикового сценария хранилища данных «Тюрьма данных»:
А) качественные данные не попадают в хранилище
Б) данные в хранилище плохо структурированы
В) данные в хранилище бесполезны для конечного пользователя
Г) доступ к данным со стороны конечного пользователя затруднен
6. Пространство значений гиперкуба OLAP называется:
А) таблица измерений
Б) таблица фактов
В) реляционная таблица
Г) информационный пакет
7. Возможные названия граней гиперкуба OLAP содержит:
А) таблица измерений
Б) таблица фактов
В) реляционная таблица
Г) информационный пакет
8. Информационный пакет хранилища данных, это:
А) таблица с требованиями к хранилищу
Б) описание входных источников данных
В) описание витрин данных хранилища
Г) модель процесса сетевого обмена пакетами хранилища и клиента