Лекция 3. Хранилище данных. Определение и компоненты.
**1.1. Определение хранилища данных. Свойства хранилищ данных**
К настоящему времени, в научных литературных источниках сформировалось достаточно большое количество разных трактовок понятия хранилище данных. Это в первую очередь связано с быстрой эволюцией технологий хранения данных (в том числе и с переходом человечества в парадигму BigData) и вносит определенные сложности в определении актуальной трактовки. Тут и далее, автор пособия будет опираться на два классических определения хранилищ данных, введёнными в оборот учеными – создателями теории и первых практических решений в области хранилищ, Б. Инмона и Ш. Келли.
Билл Инмон определяет хранилища данных, как предметно-ориентированные, интегрированные, независимые и управляемые временем коллекции данных, используемые при поддержке принятия решений.
В свою очередь, Шон Келли определяет хранилища данных по данным, хранимым в них. Данные в хранилищах данных: независимы, разделимы, доступны, интегрированы, имеют временные метки, объектно-интегрированы.
В любом случае, какое из приведенных определений не брать за основу, становится очевидно, что конструкция хранилищ данных, с точки зрения технологий хранения данных, является уникальной, самостоятельной и не зависящей ни от одной из общепринятых сегодня парадигм хранения данных. Так, в отличие от реляционной парадигмы, хранилища данных в своих свойствах не ограничиваются требованиями о целостности и согласованности данных, строгости и неделимости схем реляционных таблиц, включая обязательство нормализации таблиц для исключения аномалий. При этом, в отличие от постреляционной парадигмы, хранилища данных подразумевают разумную интеграцию и упорядоченность данных, доступных в хранилище. Таким образом, хоть хранилище и строится с использованием инструментария программного обеспечения реляционной или постреляционной парадигмы хранения данных (что будет наглядно продемонстрированно далее в тексте последующих лекций и практических работ), называть хранилища вариацией реляционной или постреляционной модели хранения данных неправильно.
Далее, определим основные свойства хранилищ данных.
1. Предметно-ориентированные данные. Хранилища данных имеют принципиально иные источники данных, нежели традиционные модели хранения. Основным источником данных для традиционных баз данных являются приложения (десктопные, мобильные, веб и т.д.). Пользователи, в рамках работы с приложениями эти данные вводят (генерируют) и сохраняют, как результат своей работы в документах или таблицах баз данных. Поскольку основная цель функционирования хранилищ данных не обслуживание пользовательских приложений, а обслуживание аналитических систем поддержки принятия решений (см. определение Инмона), то источниками данных для них уже являются не приложения, а реальные бизнес-объекты (цеха, отделы, филиалы или же предприятия в целом) или же бизнес-события (малые, средние и крупные бизнес-процессы).
2. Интегрированные данные. Мы привыкли к тому, что модель хранения данных в традиционной реляционной парадигме определяют объекты хранения (таблицы) и связи между ними. Правило простое – один объект наблюдения формирует один объект хранения. Достичь этого несложно, если набор входных данных поступает из одного источника, полностью согласован и направлен на решение прикладных задач какой-то предметной области. В хранилищах данных, в свою очередь, массив данных представляет собой комплексный агрегат из разнородных, синхронизированных друг с другом данных, получаемых из разных источников (порой, принципиально отличающихся друг от друга). Рассмотрим пример элемента хранилища данных «Банковский счет клиента». По своей сути, — это сложный агрегат, собираемый как минимум из трех потоков данных: информация о банковских вкладах клиента, информация о займах клиента и информация о балансе счета клиента. Очевидно, что эти потоки генерируются разными бизнес-процессами банка и разными его сервисами. В рамках процедур, связанных с функционированием хранилища данных, каждый из перечисленных в примере потоков данных синхронизируется с остальными, входящими в этот агрегат. Под синхронизацией, в первую очередь понимается приведение к единому виду массивов данных – их названия, используемые в них коды и системы кодирования, типы данных и единицы измерения.
3. Изменяющиеся во времени данные. Мы все помним одно из главных требований реляционной модели данных – это согласованность данных. Оно означает, что все данные, находящиеся в базе, должны быть согласованы в одном моменте времени, «здесь и сейчас». Со временем, в рамках инструментариев реляционной и постреляционной модели данных появились паттерны, позволяющие хранить и обслуживать архивные данные (которые априори не являются согласованными), но их роль до сих пор утилитарна. Учитывая же направленность хранилищ данных на аналитические и прогнозные исследования, как конечный результат функционирования (например, паттерны поведения покупателя: текущие и прогнозные), данные, находящиеся относительно друг друга в разных временных срезах (исторические, текущие, планируемые) – это основной массив данных, который будет составлять хранилище.
4. Независимые данные. Специфика наполнения и функционирования хранилищ данных подразумевает, что оно будет наполняться данными порционно, в определенные интервалы времени. Это снижает нагрузку от постоянных операций получения-загрузки данных и оставляет операционные мощности сервера хранилища данных большую часть времени свободными. В зависимости от требований бизнес-процессов, итерации загрузки данных могут производиться один раз в день, один раз в неделю, один раз в две недели. В некоторых случаях этот интервал может быть еще больше. Причем, для разных наборов данных в хранилище могут быть настроены разные интервалы данных. Например, описания продуктов для каталога можно обновлять раз в две недели, а то и режу, тогда как данные о продажах этих продуктов обновляются значительно чаще (например, каждый день). Стоит отметить, что с развитием больших данных и методов их обработки (потоковая передача больших данных или стриминг), в хранилищах данных (особенно организованных в формате облачного хранилища) все чаще практикуется передача данных в режиме «реального времени».
5. Гранулярность данных. В традиционных, реляционных моделях хранения практикует подход, когда данные собираются и хранятся с максимально доступным уровнем детализации (чтобы ничего не потеря). Например, если мы собираем данные для базы данных отдела продаж компании, мы будем стараться «вытянуть» в реляционные таблицы данные с конкретной кассы магазина, с конкретного магазина нашей сети и т.д... Контекст аналитических и прогнозных исследований подразумевает более абстрактный подход к данным, например – предварительную их агрегацию. Это означает, что один и тот же массив данных может быть представлен в хранилище с разной степенью абстракции (от менее укрупненных, более детализированных данных, до более укрупненных – предварительно агрегированных данных). Ниже, на рис. 1 показан пример разной степени гранулярности данных для данных о транзакциях пользователя в банковском хранилище данных.

Специалист по базам данных обязательно должен учитывать, что перечисленные выше свойства существенно отличают подходы по проектированию и эксплуатации хранилищ данных от привычных методов, применяемых при работе в рамках реляционной парадигмы. Для успешной работы с хранилищами данных обязательно необходимо выработать дополнительные soft и hard-skills даже в привычном программном обеспечении баз данных.
**1.2. Классическая трехуровневая архитектура хранилища данных**
Современная наука, в рамках типовой модели архитектуры хранилища данных (от которой отталкиваются при разработке конкретного проекта) определяет так называемую трехуровневую (three-tier) модель архитектуры. Называется она так потому, что сама модель состоит из трех составных частей, или уровней (tier): нижний уровень (bottom tier), средний уровень (middle tier) и верхний уровень (top tier). Такое деление на три части унаследовано из широко распространенных архитектур построения программных средств (например, веб-сервер – сервер приложений – клиентский уровень), что является более близким и понятным для специалистов, пришедших в проектирование хранилищ данных из смежных ИТ-отраслей.
В общем виде, трехуровневая архитектура хранилища данных показана на рис. 2.
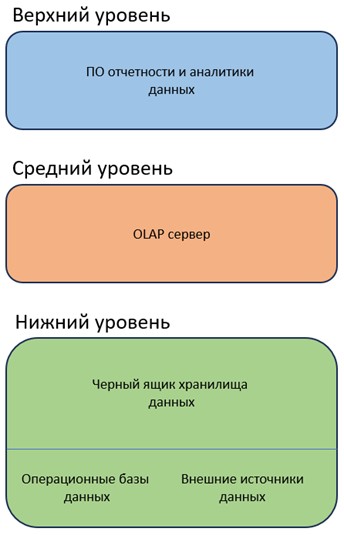
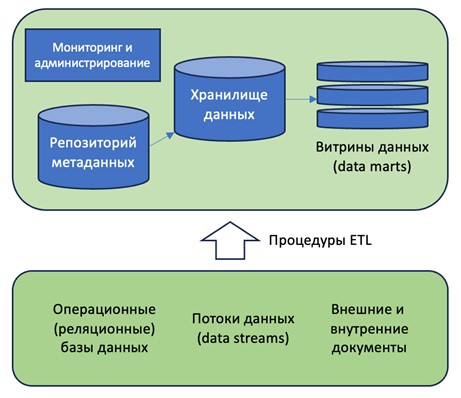
Нижний уровень архитектуры включает в себя источники информации, которые буду заполнять хранилище данных. Это могут быть промежуточные (операционные) результаты работы компании, сохраненные в реляционном или ином виде в базах данных, это могут быть внешние потоки структурированных и неструктурированных данных, «плоские» файлы и любые другие источники данных. Проходя настроенные специалистами процедуры очистки и стандартизации данных (извлечение/очистка/изменение/загрузка/обновление или extract/clean/transform/load/refresh), данные направляются в непосредственно хранилище данных, которое находится на этом же уровне модели. Помимо самого хранилища, отдельного репозитория метаданных (поскольку метаинформации у хранилища данных на порядок больше, чем у любой реляционной базы данных сравнимого масштаба, требуется управляемый отдельный репозиторий) на этом уровне присутствует инструментарий администрирования и мониторинга, а также, если это необходимо – настроенные витрины данных.
Витрина данных – это фрагмент массива данных из хранилища, выделенный из него на временной или постоянной основе для проведения аналитики данных по заранее определенным темам (например, витрина для аналитики по продажам, витрина для аналитики по складам и т.д.).
Более подробно, основные компоненты нижнего уровня архитектуры показаны на схеме, на рис. 3.
Результатом функционирования нижнего уровня архитектуры являются упомянутые выше витрины данных, или же выгрузки данных, передаваемые на следующий уровень архитектуры, на серверы OLAP (будет рассмотрено ниже, при определении среднего уровня архитектуры). Формирование витрин данных происходит там же, на нижнем уровне архитектуры. Схема движения информации при использовании в хранилище витрин данных показана на рис. 4. Предполагается, что технологией обработки данных выбрана стандартная OLTP и в процессе движения информации от источника к конечному потребителю она не меняется.
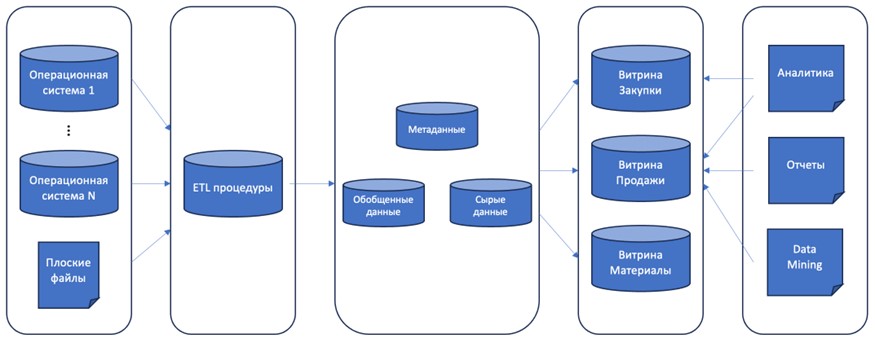
Как было указано выше, витрины данных могут формироваться как временно, так и перманентно, в последнем случае работая по аналогии с серверами-репликами баз данных. Поскольку технология обработки остается неизменной (родственная реляционной модели хранения OLTP), конечные потребители, в лице аналитиков (графическая и табличная отчетность, аналитические выкладки, добыча данных) могут напрямую обращаться к сформированным витринам из приложения или из среды управления базами данных (с помощью SQL-запросов) и получать результаты напрямую из нижнего уровня архитектуры хранилища. Приведем условия применения витрин данных вместо одного или серии прямых SQL-запросов напрямую в базе данных.
1. Необходимость изоляции данных. Актуально, когда процесс обновления данных в базе занимает значительное время (например, из-за объема обновления) и может занимать от нескольких часов. В случае применения транзакционных запросов в обычной реляционной модели, традиционные блокировки могут создать значительное количество проблем работе аналитиков. Возможность изолировать данные в рамках созданной витрины данных позволяют свободно с ними работать даже в процессе длительной загрузки или обновления данных в самом хранилище с исключением «грязного чтения» обновляемых данных. Этот процесс во многом схож с применением репликации.
2. Гарантии атомарности. В случае сбоев и ошибок при загрузке или обновлении данных, витрина данных всегда будет оставаться в состоянии, которое предшествовало сбою в системе. Гарантии аналогичные реляционной модели хранения и транзакциям – или данные обновляются правильно и полностью, или не обновляются вовсе.
3. Системная темпоральность. Одно из ключевых отличий хранилищ данных от традиционных реляционных баз – это возможность ведения системного времени и версионирование записей внутри хранилища. Витрина данных может сохранять свое состояние в разные моменты времени, что предоставляет исследователю возможность сравнивать данные, которые были в витрине в разные моменты времени, что существенно расширяет исследовательский потенциал аналитика. Данная функция, впрочем, может быть полезна и для администратора хранилища данных.
4. Витрины могут быть созданы как на нижнем уровне архитектуры хранилища для множества одновременных простых SQL-запросов (OLTP-нагрузка) или же могут быть созданы на OLAP-серверах среднего уровня архитектуры хранилища, что предоставит возможность исследователям использовать тяжелые аналитические «drilling» запросы (OLAP-нагрузка). Про разные виды запросов и нагрузок будет подробно рассказано ниже, а также на практических занятиях курса.
Средний уровень архитектуры. Если необходимо, на нем располагаются OLAP-серверы. Это программное обеспечение, аппаратное обеспечение или их сочетание, задачей которых является представление данных в многомерном виде. Грубо говоря, OLAP-сервер превращает традиционную модель хранения с таблицами и связями в модель хранения с измерениями и фактами (структура многомерных хранилищ данных будет подробно рассмотрена далее в соответствующей теме). Данные серверы могут работать в реляционной, многомерной или смешанной парадигме. Далее по тексту преимущество будет отдаваться реляционной модели OLAP-сервера (ROLAP).
Верхний уровень архитектуры – это программное обеспечение, используемое аналитиками для обработки и конечного анализа извлеченных данных. Данное ПО широко представлено различными вендорами, а выбор программных продуктов, работающих в OLAP и OLTP-нагрузке в основном зависит от поставленной перед аналитиками задачи.
**1.3. Модели хранилища данных Инмона и Кимбалла. Матрица критериев выбора модели**
В настоящий момент времени, среди проектов хранилищ данных, построенных на основании реляционной модели хранения (про постреляционную парадигму поговорим далее отдельно) выделяются две основных модели, которые были названы по фамилиям их создателей: модель Инмона и модель Кимбалла. Далее приведем основные компоненты и особенности этих вариантов построения хранилищ данных.
Модель хранилища данных Инмона в большей степени опирается на базовые постулаты теории реляционных баз данных, что подразумевает максимальное использование свойств реляционных баз данных ACID (в первую очередь - атомарности), а также процедуры, связанные с нормализацией таблиц хранилища при его моделировании. Абстрактная схема хранилища Инмона показана на рис. 5.
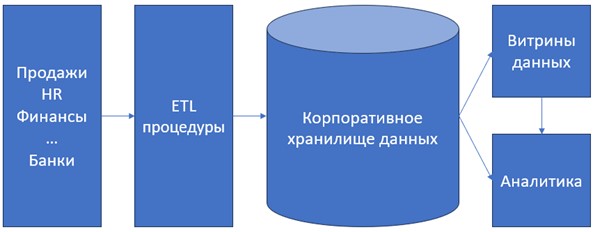
Корпоративные приложения или системы источника – блок в левой части рисунка, это системы, которые используются в операционных процессах организаций и создают данные, которыми впоследствии наполняется хранилище. Данные системы, как правило, отражают активность разных отделов хозяйствующих субъектов (продажи, управление персоналом, маркетинг, производство и пр.).
ETL процедуры или, в данной модели, - сервисы данных (data services). В рамках установленного формата, правил или политик предприятиях, на этом этапе многообразие данных из корпоративных приложений конвертируется в очищенный от ошибок и аномалий массив данных строго регламентированного образца. Процессы извлечения, обработки и загрузки данных в хранилище в модели Инмона могут выполняться в режиме пакетной передачи (batch), в режиме реального времени, или в гибридном режиме, в зависимости от особенностей функционирования и предметной области организации.
Корпоративное хранилище данных. Центральный элемент архитектуры, который содержит атомарные данные, находящиеся в третьей нормальной форме. По структуре хранения данных, это хранилище не отличается от стандартной базы данных, построенной в рамках реляционной модели.
Витрины данных. Заранее выбранные с помощью инструментов агрегации «тематические» массивы данных. Как правило, представлены в виде постоянно функционирующих реплик центрального хранилища. Отдельными витринами могут быть: витрина маркетинговых данных, витрина финансовых операций, витрина продаж и т.д... Аналитические приложения, находящиеся в правой части схемы, могут обращаться за массивами данных как к центральному хранилищу напрямую, так и к соответствующим цели исследования витринам данных.
Модель хранилища данных Кимбалла, в свою очередь, полностью отражает все особенности OLAP процессинга данных. Она значительно меньше зависит от свойств реляционной модели хранения, а некоторые из них в этой модели абсолютно неприменимы. Ключевым элементом модели является хранилище данных, построенное по принципу измерений. Абстрактная схема хранилища Кимбалла показана на рис. 6.
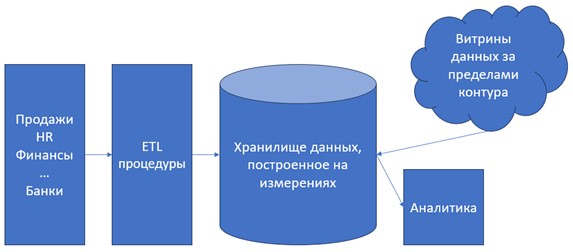
Транзакционные приложения, аналогично модели Инмона находятся в левой части контура модели и собирают информацию в рамках операционного функционирования организации.
ETL-процедуры, также аналогично модели Инмона, собирают данные из разных транзакционных приложений, очищают от аномалий и ошибок, стандартизируют в рамках принятой схемы и, наконец, передают в центральное хранилище.
Хранилище данных, построенное на измерениях. Содержит корпоративные данные в виде, наиболее удобном для проведения процедур «data drilling». Это один из методов анализа данных, когда исследователь углубляется в исследование массива данных, конкретизируя запрос на каждой последующей итерации (переходит на другой уровень грануляции). Для обеспечения этих процедур, при построении хранилища используется модель, когда все таблицы становятся измерениями (подробнее об этом в последующих лекциях). Модель может быть организована по типу «звезда» или «снежинка». Как правило, аналитические системы, при применении этой модели, извлекают данных напрямую из хранилища, а не из витрин данных, как в случае с моделью Инмона.
Витрина данных (datamart). В данном модели чаще всего выполняет утилитарные функции, существует за пределами хранилища (в репликационном виде).
Выбор одной из двух приведенных моделей осуществляется при реализации проекта разработки хранилища данных архитектором проекта, и зависит от многих факторов, большинство из которых приведены на рис. 7.
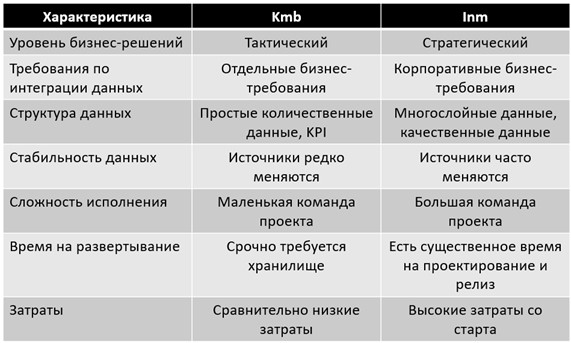
Важно отметить, что, ввиду существенной разницы двух моделей, после реализации проекта хранилища данных, процесс замены одной модели на другую сравним по затратам с целом проектом разработки, поэтому к обоснованию выбора модели следует подходить максимально ответственно.